ポアソン分布は、離散的なカウントデータを扱うための重要な確率分布です。この分布は、一定期間内や一定の空間内で稀に発生する事象の回数をモデル化するために広く用いられます。例えば、1時間にコールセンターにかかってくる電話の件数や、1平方メートルあたりのある種類の植物の数など、事象の発生回数が整数で数えられるようなデータに適用されます。
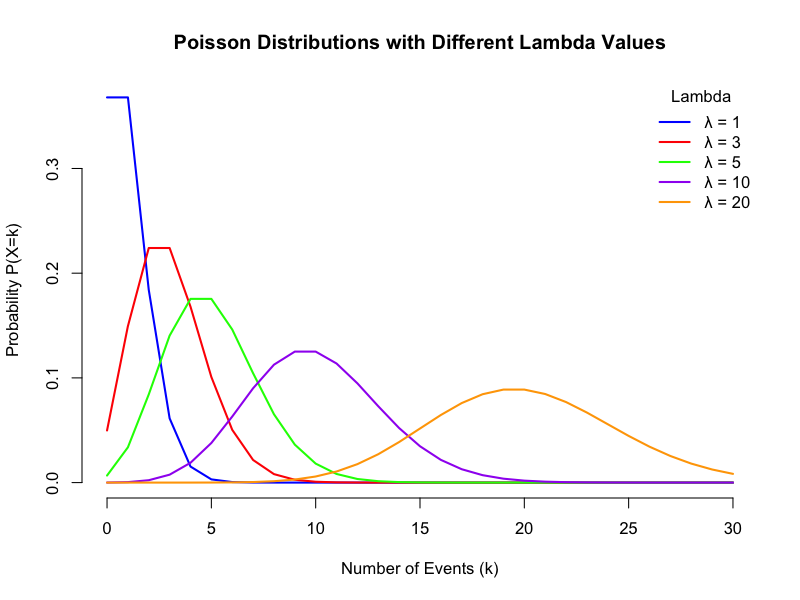
(図:ポアソン分布)
ポアソン分布の定義とパラメータ
ポアソン分布は、唯一のパラメータであるλ(ラムダ)によって完全に決定されます。λは、対象となる期間や空間における事象の平均発生回数を表します。
確率変数X(起こりうる結果の値を表す変数)がポアソン分布に従うとき、その確率質量関数(離散的な確率変数において、特定の値が発生する確率を示す関数)P(X=k)は、以下の式で表されます。
$$ P(X=k) = \frac{\lambda^k e^{-\lambda}}{k!} $$
ここで、kは事象の発生回数(k=0,1,2,…)、λは平均発生回数、そしてeは自然対数の底(約2.718の定数)です。この式は、平均λのときに、事象がちょうどk回発生する確率を計算します。
ポアソン分布の重要な性質
ポアソン分布には、その理論的な背景と応用において極めて重要な特性があります。
- 平均と分散の一致:ポアソン分布の最も特徴的な性質は、平均と分散が等しいということです。つまり、μ=σ²=λが常に成り立ちます。この性質は、実データがこの仮定を満たすかを確認する際の重要な指標となります。もしデータの分散が平均より著しく大きい場合(過分散:データのばらつきが理論値より大きい状態)、ポアソン分布は適切なモデルではない可能性があり、負の二項分布(Negative Binomial Distribution:過分散に対応できる分布)などの別のモデルを検討する必要があります。
- 加法性:独立な複数のポアソン分布に従う確率変数の和は、再びポアソン分布に従います。例えば、ある支店Aで1時間あたりの来客数がポアソン分布P(λ_A)に従い、支店Bの来客数がポアソン分布P(λ_B)に従うとします。このとき、両支店の合計来客数は、ポアソン分布P(λ_A + λ_B)に従うことになります。
- 稀な事象のモデル:ポアソン分布は、二項分布(成功・失敗の2つの結果を持つ試行を繰り返したときの成功回数の分布)の極限として導出されます。試行回数nが非常に大きく、事象の発生確率pが非常に小さい場合、二項分布はポアソン分布に近似されます。これは、ポアソン分布がなぜ「稀な事象」をモデル化するのに適しているかを説明します。
ポアソン過程の仮定
ポアソン分布を適用するためには、データがポアソン過程(Poisson Process:事象がランダムに発生する過程を数学的にモデル化したもの)と呼ばれる以下の4つの仮定を満たしている必要があります。
- 独立性:ある期間や空間での事象の発生は、他の期間や空間での発生とは独立しています。つまり、事象の発生が他の事象の発生に影響を与えません。
- 定常性:単位時間(や単位空間)あたりの平均発生率λは一定です。時間帯や場所によって発生率が変わる場合は、この仮定が満たされません。
- 稀な事象:非常に短い時間間隔や非常に小さな空間内で、複数の事象が同時に発生する確率はゼロと見なせます。
- 連続性:単位時間あたりの事象の発生数は、無限に細かく分割された時間間隔で数えることができます。
これらの仮定は、現実のデータに適用する際の重要なチェックポイントとなります。
ポアソン分布の応用事例
- コールセンターの着信数:あるコールセンターに1時間あたりにかかってくる電話の件数は、ポアソン分布に従うことがよくあります。過去のデータから平均着信数λを推定することで、特定の時間帯に何件の電話がかかってくる確率が高いかを計算し、必要なオペレーターの数を適切に配置することができます。
- Webサイトへのアクセス数:Webサイトのアクセス数も、ポアソン分布を適用できる典型的な例です。1分あたりのページビュー数や、1時間あたりの新規ユーザー登録数などを分析することで、サーバーの負荷を予測し、システムを最適化するのに役立ちます。
- 製造業における不良品発生数:製造ラインで生産される製品のうち、1日あたりの不良品の数は、ポアソン分布でモデル化されることがあります。これにより、不良品の発生率を管理し、品質改善のターゲットを立てることができます。
- 災害発生や事故件数:ある地域での1年間の地震の発生件数や、特定の交差点での1ヶ月間の交通事故件数など、稀に発生する事象の分析にも用いられます。
- バイオインフォマティクス
DNA配列(遺伝情報を記録する分子の並び)上の特定の変異の数や、細胞内の遺伝子発現(遺伝子の情報が実際にタンパク質として現れること)のカウントデータなど、生物学的なデータのモデリングにも応用されます。
ポアソン分布の限界と代替モデル
ポアソン分布は強力なツールですが、前述のポアソン過程の仮定が満たされない場合には注意が必要です。
- 過分散(Over-dispersion):実データにおいて、分散が平均よりもはるかに大きい場合が多々あります。これは、事象の発生が独立ではなく、群生(clustering:同じような事象がまとまって発生すること)している場合に起こります。例えば、特定の時間帯に顧客が集中して来店するような場合です。このような過分散データには、負の二項分布(Negative Binomial Distribution)がより適しています。負の二項分布は、ポアソン分布に加えて分散を調整するパラメータを持つため、過分散に対応することができます。
- ゼロ過剰(Zero-inflated):ポアソン分布はカウントがゼロである事象もモデル化しますが、ゼロが過剰に多い場合も問題となります。例えば、ある病院の受診件数データで、多くの患者が一度も来院しない(ゼロの件数が多い)ような場合です。このようなデータには、ゼロ過剰ポアソン分布(Zero-Inflated Poisson, ZIP:ゼロの発生を特別に考慮したポアソン分布の拡張)やゼロ過剰負の二項分布(Zero-Inflated Negative Binomial, ZINB)といった専門的なモデルが用いられます。
まとめ
ポアソン分布は、単位期間や空間内での事象の発生回数をモデル化する上で、非常に有用な確率分布です。その単純さと、平均と分散が一致するという強力な性質は、多くの分野で実用的な分析を可能にしています。
しかし、その適用には、事象の独立性や定常性といったポアソン過程の仮定が満たされているかを慎重に検討することが重要です。これらの仮定が崩れる場合には、負の二項分布などのより柔軟なモデルを検討することが、分析の精度を高める上で不可欠となります。データの特性を十分に理解し、適切なモデルを選択することで、ポアソン分布の持つ力を最大限に活用することができるのです。
")
{kind=link}