カイ二乗分布は、複数の独立な標準正規分布に従う確率変数の二乗和として定義される連続確率分布です。この分布は、統計学において「観測されたデータが、理論的な期待からどのくらいずれているか」を評価する際の基盤となる重要な分布です。正規分布やt分布が主に平均値や比率を扱うのに対し、カイ二乗分布は全く異なる目的で使われます。
(図:カイ二乗分布)
定義とパラメータ
カイ二乗分布は、自由度(degrees of freedom, df)という単一のパラメータによってその形状が決定されます。この自由度は、分布を定義する独立した標準正規分布に従う確率変数の個数に等しいです。
$Z_1, Z_2, \ldots, Z_k$が、それぞれ独立に標準正規分布$N(0,1)$に従う確率変数であるとします。このとき、これらの二乗和として定義される確率変数$X$は、自由度$k$のカイ二乗分布に従います。
$$X = Z_1^2 + Z_2^2 + \cdots + Z_k^2 \sim \chi^2_k$$
ここで、$\chi^2$はギリシャ文字の「カイ」の二乗であり、「カイ二乗」と読みます。
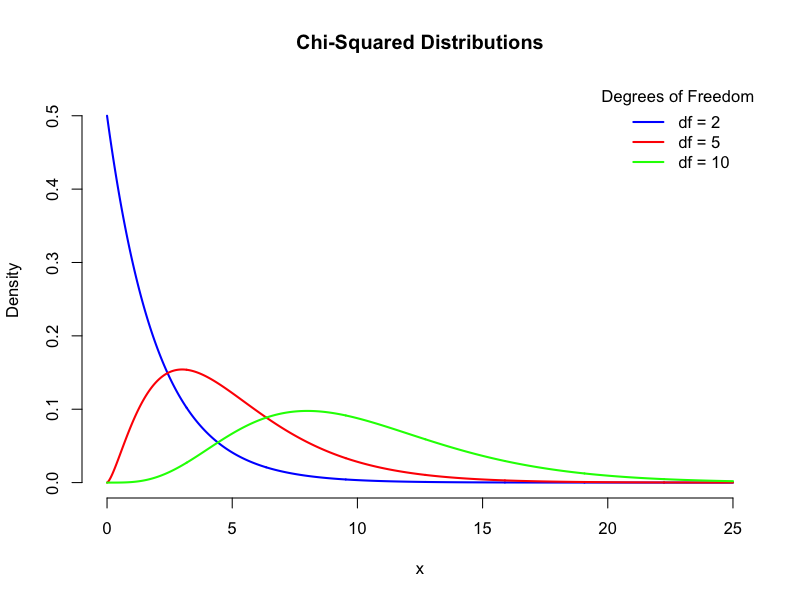
非対称で非負の形状
カイ二乗分布は、自由度の値によって形状が大きく変化する特徴的な分布です。
非対称性
カイ二乗分布は常に非負の値をとり、右に裾が長い(正の歪度を持つ)非対称な形状をしています。これは、二乗和として定義されるため、負の値を取ることがないためです。
自由度との関係
- 自由度が小さいとき(例:$df=1,2$): 分布は急激に右に減少し、0に近い値の確率が最も高くなります
- 自由度が増加するにつれて: 分布のピークは右に移動し、より対称的なベル型に近づいていきます
- 自由度が30以上: カイ二乗分布は正規分布に非常に近い形状となり、正規分布として近似することが可能になります
カイ二乗検定
カイ二乗分布は、主にカイ二乗検定の検定統計量(仮説検定で計算される統計的指標)が従う分布として利用されます。カイ二乗検定は、カテゴリカルデータ(名義尺度データ:性別、血液型など分類のためのデータ)を扱う際に特に強力なツールであり、以下の2つの主要な目的で使われます。
1. 独立性の検定(Test of Independence)
これは、2つのカテゴリ変数間に統計的に有意な関連があるかを検定する際に用いられます。
例:性別とスマートフォンOS
性別(男性、女性)と、スマートフォンのOS(iOS、Android)という2つのカテゴリ変数があるとします。
- 帰無仮説($H_0$): 「性別」と「スマートフォンのOS」には関連がない(独立である)
- 対立仮説($H_1$): 「性別」と「スマートフォンのOS」には関連がある(独立ではない)
この検定では、実際に観測されたデータの度数分布表(分割表:各カテゴリの組み合わせでのデータの個数を示す表)と、帰無仮説が正しい場合に期待される理論的な度数分布表を作成します。そして、両者の間の「ズレ」を測るために、以下のカイ二乗統計量を計算します。
$$\chi^2 = \sum \frac{(\text{観測度数} – \text{期待度数})^2}{\text{期待度数}}$$
この統計量が従う分布が、カイ二乗分布です。計算された$\chi^2$値が、対応する自由度($df = (\text{行数}-1) \times (\text{列数}-1)$)のカイ二乗分布上のどの位置にあるかを確認し、p値(帰無仮説が正しい場合にこのような結果が得られる確率)を計算します。p値が有意水準(通常0.05)よりも小さければ、2つの変数間には関連があると結論付けられます。
2. 適合度検定(Goodness-of-Fit Test)
これは、観測されたデータが、ある特定の理論的な分布(例:一様分布、正規分布など)にどの程度適合しているかを検定する際に用いられます。
例:サイコロの公正性
あるサイコロが公正であるか(つまり、各面が出る確率が1/6であるか)を検定したいとします。
- 帰無仮説($H_0$): サイコロは公正であり、各面が出る確率は1/6である
- 対立仮説($H_1$): サイコロは公正ではない
実際にサイコロを120回投げ、各面が出た回数を記録します。
- 観測度数: 実際に得られた各面の出た回数
- 期待度数: 帰無仮説が正しい場合に期待される回数(120回投げた場合、各面が$120 \times (1/6) = 20$回出る)
この2つの度数分布間の「ズレ」を、先ほどと同じカイ二乗統計量で計算します。この場合、自由度は$df = (\text{カテゴリ数}-1)$で計算されます。
応用事例
カイ二乗分布は、様々な分野で重要な役割を果たしています。
市場調査
新商品のパッケージデザインA、B、Cのうち、消費者がどのデザインを最も好むか?性別によって好みに差があるか?などを、アンケート調査のデータから分析します。
医療
ある薬の副作用の発現率が、人種によって異なるかを検定します。臨床試験(新しい治療法の効果や安全性を確認するための試験)でのデータ分析に頻繁に用いられます。
社会学
ある地域における政党支持率が、年齢層によって差があるかを検証します。世論調査(社会の意見や態度を調べる調査)の分析にも活用されます。
遺伝学
メンデルの法則(遺伝の基本法則)に従って、エンドウ豆の種の色と形の比率が特定の比率(例:9:3:3:1)になるかを検定します。
品質管理
製造工程で発生する不良品の種類が、特定のパターンに従っているかを検証し、工程改善の指針を得ます。
まとめ
カイ二乗分布は、データの「ズレ」を測るという、統計的推論において非常に重要な役割を果たします。
主要な特徴
- 定義: 独立な標準正規分布に従う確率変数の二乗和として定義される
- 自由度: 唯一のパラメータであり、分布の形状を決定する
- 形状: 常に非負で、右に歪んだ非対称な分布
重要な応用
- 独立性の検定: 2つのカテゴリ変数間の関連性を検証
- 適合度検定: データが特定の理論的分布に適合するかを検証
カイ二乗分布を理解することで、単に平均を比較するだけでなく、変数間の関係性や、データが特定のモデルに適合するかどうかを、統計的に厳密に評価できるようになります。特に、質的データ(カテゴリデータ)の分析においては、カイ二乗検定は不可欠なツールであり、現代のデータ分析において広範囲にわたって活用されています。
")

{kind=link}