記述統計量(Descriptive Statistics)は、データセットの本質的な特徴を要約し、その構造を簡潔に理解するための統計的手法です。これらの数値は、生データを集約し、中心、ばらつき、および分布の形状を明らかにすることで、その後の推測統計学の分析(例:仮説検定、回帰分析)に不可欠な基礎を提供します。
中心傾向の尺度(データの代表値)
データがどこに集まっているか、その「中心」を代表する値を見つけるための指標群です。データセット全体を一つの数値で要約する役割を担います。
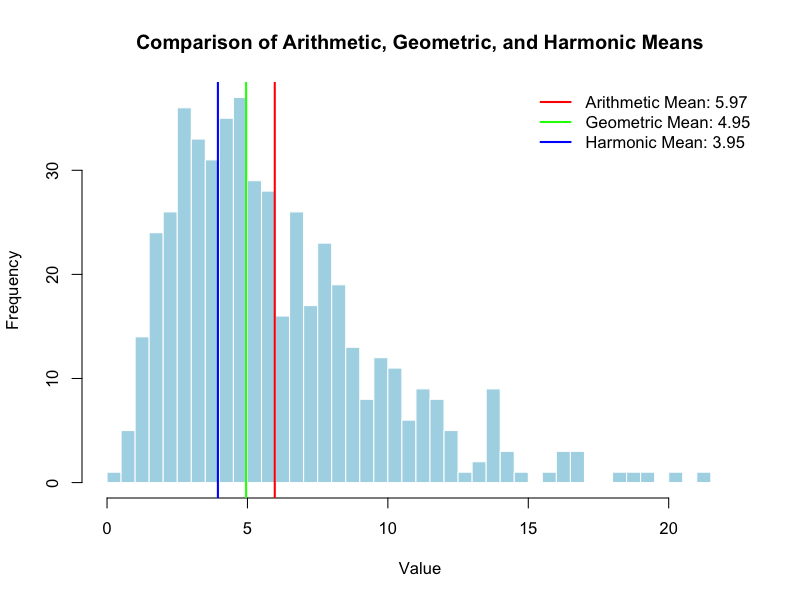
平均値(Mean)
(図:平均値)
最も広く知られ、使用される代表値です。データセットの重心に相当します。
算術平均(Arithmetic Mean)
すべての観測値を合計し、その観測数で割った値です。
$$ \bar{x} = \frac{1}{n}\sum_{i=1}^{n} x_i $$
直感的に理解しやすく、数学的な扱いが容易であるため、多くの統計的手法の基礎となります。しかし、その最大の弱点は外れ値(outlier)に非常に敏感であることです。例えば、ある会社の従業員10人の給与が全員30万円であるときに、社長の給与が1億円だった場合、平均給与は930万円となり、従業員の実態を全く反映しない値となります。このため、歪んだ分布を持つデータには適さない場合があります。
幾何平均(Geometric Mean)
n個の正の観測値をすべて掛け合わせ、その積のn乗根を求めます。
$$ G = \sqrt[n]{x_1 \times x_2 \times \dots \times x_n} $$
主に比率や成長率の平均を計算する際に使用されます。例えば、ある投資が3年間で年率10%, 20%, 30%の成長を遂げた場合、算術平均は20%ですが、実際の複合成長率を計算するには幾何平均を用いるのが適切です。算術平均よりも小さな値となり、長期的な成長の平均をより正確に表します。
調和平均(Harmonic Mean)
観測値の逆数の算術平均の逆数として計算されます。
$$ H = \frac{n}{\sum_{i=1}^{n} \frac{1}{x_i}} $$
速度や価格など、率や比率の平均を計算する際に用いられます。例えば、「往路は時速40km、復路は時速60km」の場合、単純な平均速度は50kmではありません。往復の距離と時間を計算すると、実際の平均速度は48kmとなり、これは調和平均と一致します。
中央値(Median)
データセットを2つの等しい部分に分ける、真ん中の値です。データを小さい順に並べ、中央に位置する値を見つけます。
- データ数が奇数:中央の1つの値が中央値となります。
- データ数が偶数:中央の2つの値の平均が中央値となります。
平均値と異なり、外れ値の影響を受けにくいという最大の強みがあります。このため、不動産価格や個人の所得など、少数の極端な値を持つデータセットの代表値として非常に有用です。平均値と中央値の差は、データの歪み(後述)を示す重要な指標となります。
最頻値(Mode)
データセット内で最も頻繁に出現する値です。
平均値や中央値が使えない名義尺度データ(例:好きな色、交通手段)に対しての代表値として機能します。データセットによっては、最頻値が複数存在する場合(二峰性、多峰性)もあり、これはデータが複数のグループに分かれている可能性を示唆する重要な手がかりとなります。例えば、顧客の年齢層のデータで最頻値が20代と50代に存在する場合、その製品は若年層と中高年層の両方に人気があることを示します。
ばらつきの尺度(データの散らばり)
データが中心からどれだけ散らばっているか、その広がりを示すための指標です。これらの尺度は、データの「多様性」や「一貫性」を評価する上で不可欠です。
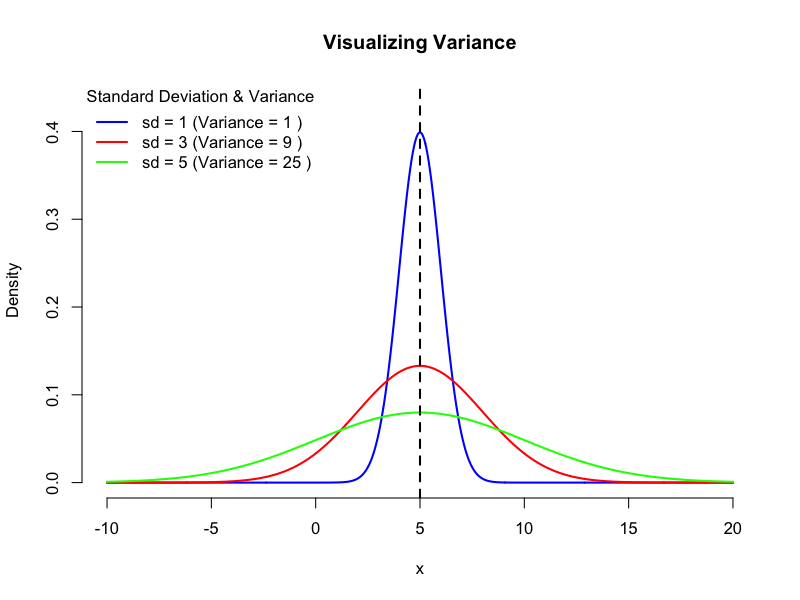
分散(Variance)
(図:分散)
各観測値と平均値との差(偏差)を二乗し、それらの平均を求めます。
$$\text{母分散 } \sigma^2 = \frac{1}{N}\sum_{i=1}^{N} (x_i – \mu)^2$$
$$\text{標本分散 } s^2 = \frac{1}{n-1}\sum_{i=1}^{n} (x_i – \bar{x})^2$$
数学的な扱いが容易であるため、多くの統計的検定やモデル構築の基礎となります。しかし、単位が元のデータの単位の二乗となるため(例:身長データがcmなら分散はcm²)、直感的な解釈は難しいです。
また、n−1で割る(ベッセルの補正)理由は、標本分散を計算する際に分母をnではなくn−1とすることで、母分散をより正確に推定できることが数学的に証明されています。これは、「標本平均を計算する際に、自由に変動できるデータの数が1つ失われる」と解釈されます。
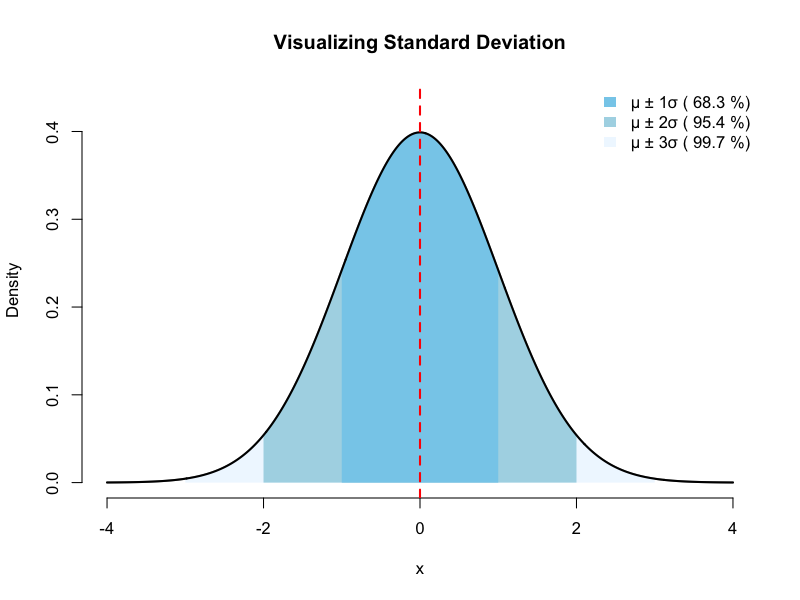
標準偏差(Standard Deviation)
(図:標準偏差)
分散の正の平方根です。これにより、データのばらつきを元のデータの単位に戻すことができます。
$$\text{母標準偏差 } \sigma = \sqrt{\frac{1}{N}\sum_{i=1}^{N} (x_i – \mu)^2}$$
$$\text{標本標準偏差 } s = \sqrt{\frac{1}{n-1}\sum_{i=1}^{n} (x_i – \bar{x})^2}$$
分散と異なり、元の単位でばらつきを表すため、直感的に理解しやすいのが最大の利点です。例えば、テストの平均点が70点で標準偏差が5点であれば、「多くの学生の点数は65点から75点の範囲に集中している」と容易に想像できます。
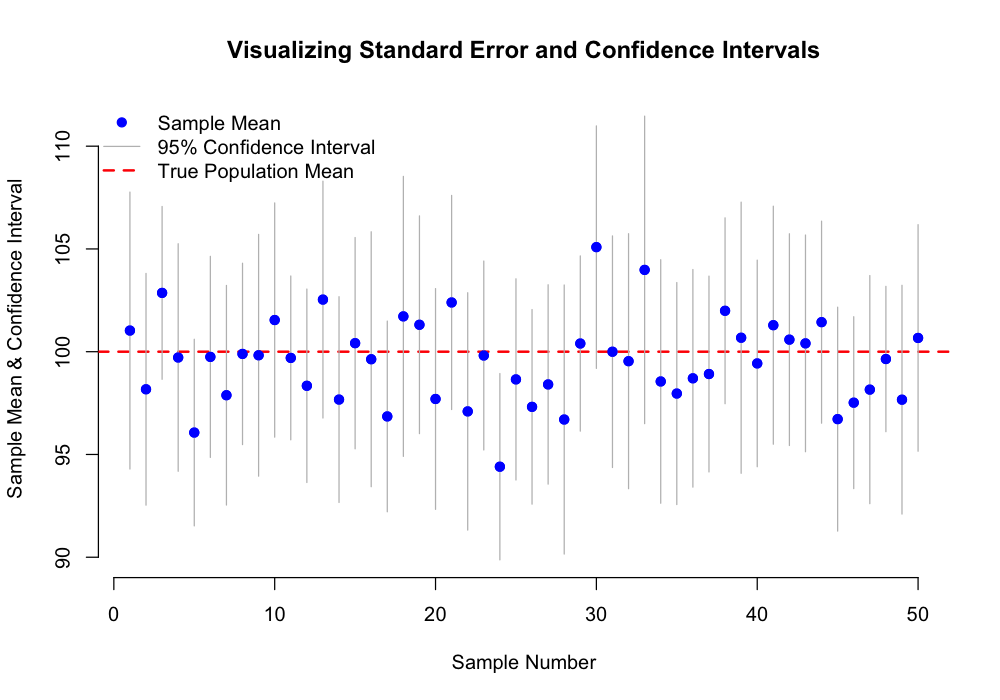
標準誤差(Standard Error)
(図:標準誤差)
標準偏差と混同されがちですが、その意味合いは大きく異なります。標本標準偏差をサンプルサイズの平方根で割った値です。
$$SE_{\bar{x}} = \frac{s}{\sqrt{n}}$$
これはデータのばらつきではなく、標本平均のばらつきを示す尺度です。つまり、「同じ母集団から異なる標本を何度も抽出したとき、その標本平均がどれくらいばらつくか」を表します。標準誤差が小さいほど、その標本平均が母集団の平均をより正確に推定していると判断できます。信頼区間の計算や統計的検定に不可欠な値です。
四分位数(Quartiles)と四分位範囲(IQR)
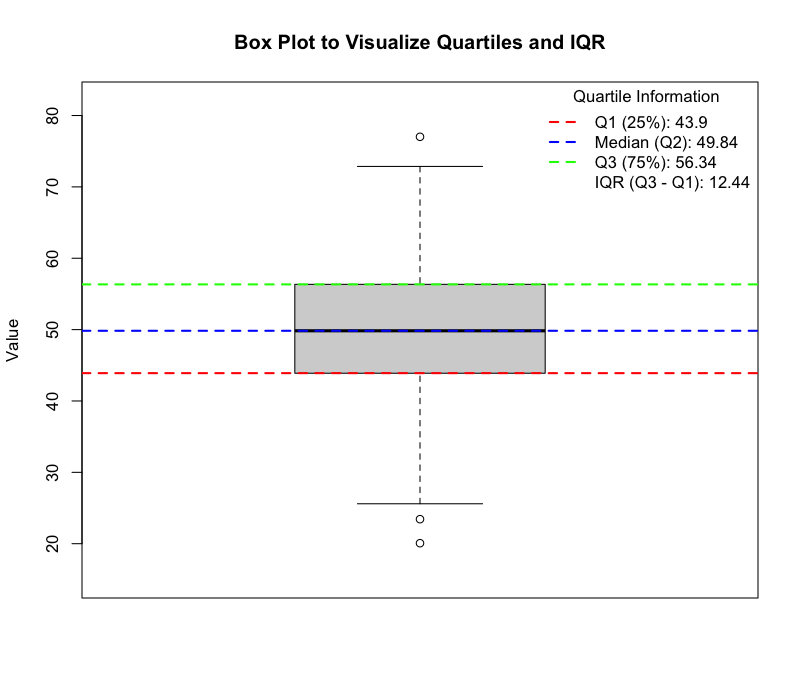
(図:四分位数と四分位範囲)
中央値が外れ値に強いように、これらも外れ値に強いばらつきの尺度です。
四分位数(Quartiles)
データを小さい順に並べ、4等分する3つの値です。
- 第1四分位数(Q1):データの25%の位置にある値。
- 第2四分位数(Q2):データの50%の位置にある値(中央値と同じ)。
- 第3四分位数(Q3):データの75%の位置にある値。
四分位範囲(IQR)
Q3とQ1の差(IQR=Q3−Q1)です。データの真ん中50%のばらつきを示すため、極端な外れ値の影響を受けません。箱ひげ図(Box Plot)の基礎となります。
変動係数(Coefficient of Variation)
標準偏差を平均値で割った値です。
$$CV = \frac{s}{\bar{x}}$$
単位を持たない相対的なばらつきの尺度です。平均値や単位が大きく異なる複数のデータセット(例:体重と身長、異なる通貨の株価)のばらつきを比較する際に非常に有用です。値が大きいほど、データはより不均一であると判断できます。
分布の形状の尺度
データが正規分布からどのくらい乖離しているか、その形状を数値で表現する指標です。
歪度(Skewness)
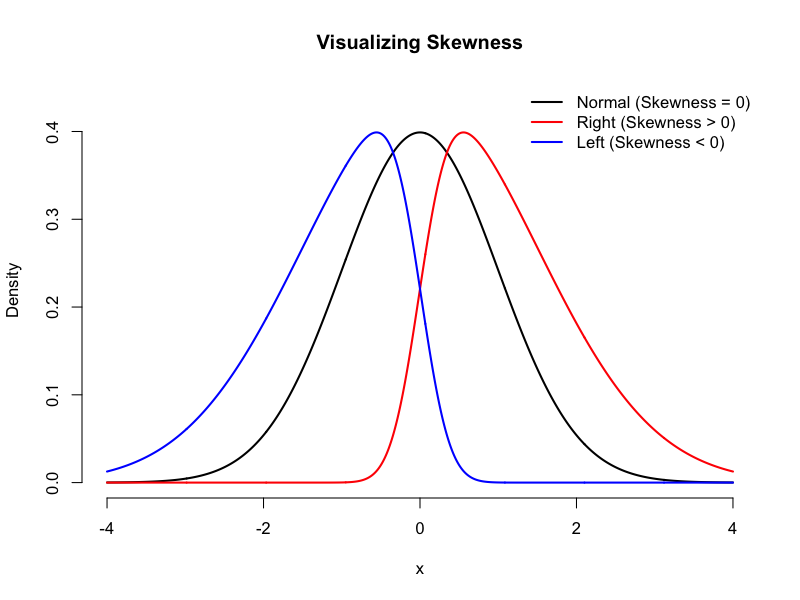
(図:歪度)
分布の左右対称性を示します。
$$\text{歪度} = \frac{\sum_{i=1}^{n} (x_i – \bar{x})^3}{(n-1)s^3}$$
- 歪度 = 0:正規分布のように左右対称な分布です。平均値、中央値、最頻値がすべて一致します。
- 正の歪度(Right-skewed):分布の山が左に偏り、裾が右に長く伸びている状態です。極端に大きな外れ値が存在する場合によく見られます。所得データのように、平均値 > 中央値 > 最頻値となります。
- 負の歪度(Left-skewed):分布の山が右に偏り、裾が左に長く伸びている状態です。極端に小さな外れ値が存在する場合によく見られます。高得点が集中したテストの点数のように、平均値 < 中央値 < 最頻値となります。
尖度(Kurtosis)
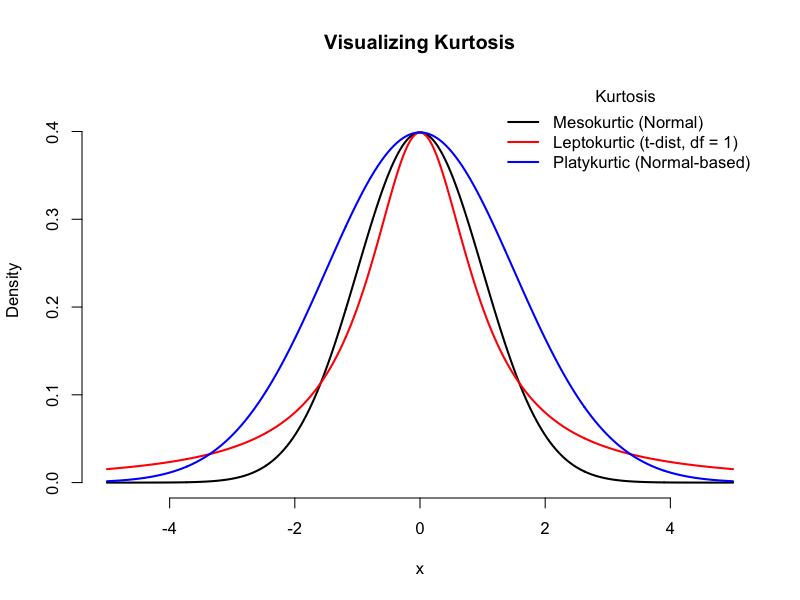
(図:尖度)
分布の山の尖り具合と裾の厚さを示します。
$$\text{尖度} = \frac{\sum_{i=1}^{n} (x_i – \bar{x})^4}{(n-1)s^4} – 3$$
- 超過尖度 = 0(Mesokurtic):正規分布と同じ尖り具合です。
- 正の超過尖度(Leptokurtic):山が正規分布より尖り、裾が厚い状態です。これは、平均値付近にデータが集中し、外れ値の発生頻度が高いことを示唆します。金融市場の株価リターンなど、極端な変動が頻繁に起こるデータでよく見られます。
- 負の超過尖度(Platykurtic):山が正規分布より平坦で、裾が薄い状態です。データが比較的均等に分布していることを示唆します。
記述統計量の組み合わせと視覚化
個々の記述統計量は、単独でも有用ですが、それらを組み合わせて総合的に評価し、グラフと組み合わせて視覚化することで、データの真の姿を明らかにできます。
- ヒストグラム(Histogram):データの分布の形状、歪度、尖度を視覚的に捉えるのに最適です。
- 箱ひげ図(Box Plot):中央値、四分位数、IQR、および外れ値を一度に視覚化できます。複数のグループを比較する際にも非常に有効です。
- 散布図(Scatter Plot):2つの変数の関係性やパターン(相関)を視覚的に示し、外れ値の特定にも役立ちます。
まとめ
記述統計量は、複雑なデータの世界を探索するための、最初のそして最も重要なステップです。中心傾向、ばらつき、分布の形状という3つの視点からデータを要約することで、私たちはそのデータの基本的な性質を深く理解することができます。
この理解は、その後の分析(例:データの正規性を前提とするパラメトリック検定や、回帰分析)において、適切な手法を選択するための確固たる基盤を築きます。データ分析の旅は、この単純でありながら奥深い「記述」から始まります。
")

{kind=link}