統計的推論は、多くの場合、データの背後にある確率分布について特定の仮定を置きます。これらの仮定が満たされない場合、検定の有効性や、モデルから得られる推定値の信頼性は著しく低下します。本節では、統計モデルで一般的に要求される3つの重要な前提条件、すなわち正規性、等分散性、そして比例ハザード性の検証方法について、その理論的背景と実践的な適用法を詳細に論じます。
正規性検定
正規性検定は、データ(特にモデルの残差や特定の変数)が正規分布に従うという前提を検証するための手法です。正規分布は多くのパラメトリックな統計手法(例:t検定、ANOVA、線形回帰)の基礎をなすため、この前提の検証は極めて重要です。正規性の仮定が満たされない場合、p値の計算が不正確になり、第一種または第二種の過誤の確率が意図した水準からずれる可能性があります。
シャピロ・ウィルク検定(Shapiro-Wilk Test)
データを昇順に並べ、その順序統計量と、同じ平均と分散を持つ正規分布の期待値との相関を評価する検定です。検定統計量$W$は、相関の強さを示す値であり、$W$が1に近いほど正規性が高いと判断されます。
数式
検定統計量$W$は、以下の式で定義されます。
$$W = \frac{\left( \sum_{i=1}^n a_i x_{(i)} \right)^2}{\sum_{i=1}^n (x_i – \bar{x})^2}$$
ここで、$x_{(i)}$は$i$番目の順序統計量、$a_i$は定数、$\bar{x}$は標本平均です。
特徴
サンプルサイズが50未満の比較的小さい標本に対して、非常に高い検出力(検定力)を持つことで知られています。この高い検出力から、正規性の検証においては最も推奨される手法の一つとされています。
帰無仮説 ($H_0$)
データは正規分布から抽出されたものである。
結果の解釈
p値が有意水準(通常は$p<0.05$)を下回った場合、帰無仮説は棄却され、「データは正規分布に従わない」と結論付けられます。ただし、サンプルサイズが非常に大きい場合、わずかな非正規性でも統計的に有意な結果が出やすくなるため、p値だけでなく、後述するグラフィカルな手法と併用して判断することが推奨されます。
コルモゴロフ・スミルノフ検定(Kolmogorov-Smirnov Test, K-S Test)
観測されたデータの累積分布関数(ECDF)と、仮定された理論分布(例:正規分布)の累積分布関数との間の最大差を測定する検定です。この最大差を検定統計量$D_n$として用います。
数式
検定統計量$D_n$は、以下の式で定義されます。
$$D_n = \sup_x |F_n(x) – F(x)|$$
ここで、$F_n(x)$は経験累積分布関数、$F(x)$は仮定した理論分布の累積分布関数です。
特徴
サンプルサイズが50以上の比較的大きい標本に推奨されます。この検定の主要な限界は、理論分布のパラメータ(平均と標準偏差)をデータから推定した場合、検出力が低下することです。このため、実際には、その改良版であるリリーフォース検定(Lilliefors Test)や、より検出力の高いアンドーソン・ダーリング検定(Anderson-Darling Test)が広く用いられます。アンドーソン・ダーリング検定は、分布の裾(テール)部分に重み付けをして検定を行うため、裾の非正規性に対する検出力が高いという利点があります。
帰無仮説 ($H_0$)
観測データと理論分布は同じ分布から抽出されたものです。
Q-Qプロット
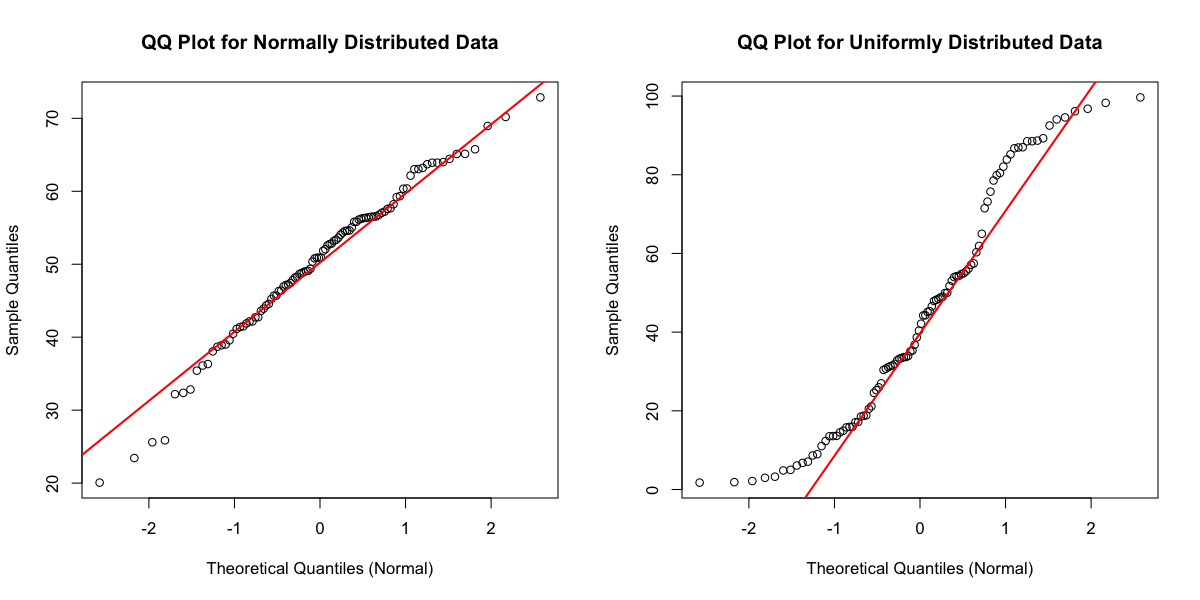
(図:Q-Qプロット)
正規性検定は統計的な有意性を示しますが、データの分布の性質を視覚的に理解することも極めて重要です。Q-Qプロット(Quantile-Quantile Plot)は、データの分位点と理論的な正規分布の分位点を比較する散布図です。
理想的な正規分布
もしデータが正規分布に従う場合、プロットされた点はほぼ直線上に並びます。
歪度(Skewness)
プロットがS字型に曲がる場合、分布に歪み(非対称性)が存在することを示唆します。S字が上向きであれば正の歪度、下向きであれば負の歪度を持ちます。
尖度(Kurtosis)
プロットがU字型に曲がる場合、分布の尖り(裾の広がり)が正規分布と異なることを示します。U字が下向きであれば尖度が小さく(裾が薄い)、上向きであれば尖度が大きい(裾が厚い)ことを意味します。
利用法
Q-Qプロットは、検定結果を補完し、データの非正規性がどのような形であるか(例:裾が重い、左右に歪んでいる)についての直感的な洞察を与えます。
等分散性検定
等分散性(Homoscedasticity)は、複数のグループまたは変数間の分散が均一であるという前提です。この前提は、ANOVAや独立したt検定など、複数のグループの平均を比較する多くの手法に不可欠です。等分散性の前提が破られる不均一分散(Heteroscedasticity)の場合、推定された標準誤差が不正確になり、検定統計量の信頼性が失われます。
F検定(F-Test)
2つの群間の分散の比率を評価する検定です。検定統計量$F$は、2つの標本分散の比として計算されます。
数式
検定統計量$F$は、以下の式で定義されます。
$$F = \frac{s_1^2}{s_2^2}$$
ここで、$s_1^2$と$s_2^2$は、それぞれの群の標本分散です。
特徴
非常にシンプルですが、データの正規性に極めて敏感であり、非正規性の影響を強く受けて誤った結論を導き出す可能性があります。このため、実務ではあまり推奨されません。
帰無仮説 ($H_0$)
2つの群の分散は等しい($\sigma_1^2 = \sigma_2^2$)。
バートレット検定(Bartlett’s Test)
3つ以上の群の分散が等しいかどうかを比較するための検定です。
数式
検定統計量$\chi^2_{obs}$は、以下の式で定義されます。
$$\chi^2_{obs} = \frac{(N-k)\ln(s_p^2) – \sum_{i=1}^k (n_i-1)\ln(s_i^2)}{1 + \frac{1}{3(k-1)} \left( \sum_{i=1}^k \frac{1}{n_i-1} – \frac{1}{N-k} \right)}$$
ここで、$N$は全標本サイズ、$k$は群の数、$n_i$は群$i$の標本サイズ、$s_i^2$は群$i$の標本分散、$s_p^2$は全標本を統合した分散です。
特徴
データが正規分布に従う場合に非常に高い検出力を持つ一方で、正規性の仮定からのわずかな逸脱に対しても敏感に反応し、誤って等分散性の前提を棄却してしまうことが最大の弱点です。
レーベン検定(Levene’s Test)
各群の観測値と中央値(または平均)からの絶対偏差を用いて、分散の均一性を検定します。この検定の本質は、各群の絶対偏差に対してANOVAを行うことです。
数式
検定統計量$F$は、ANOVAのF統計量として計算されます。
$$F = \frac{MS_{Between}}{MS_{Within}} = \frac{\frac{1}{k-1}\sum_{i=1}^k n_i(\bar{Z}_{i\cdot} – \bar{Z}_{\cdot\cdot})^2}{\frac{1}{N-k}\sum_{i=1}^k \sum_{j=1}^{n_i} (Z_{ij} – \bar{Z}_{i\cdot})^2}$$
ここで、$Z_{ij}$は、観測値$Y_{ij}$と群の平均(または中央値)との絶対偏差です。
特徴
正規性の仮定が保証できない場合でも頑健な結果を出すため、バートレット検定よりも広く推奨されます。絶対偏差の代わりに二乗偏差を用いたブラウン・フォーサイス検定(Brown-Forsythe Test)も同様に頑健です。多くの統計パッケージでは、ANOVAの等分散性検定としてデフォルトで採用されています。
帰無仮説 ($H_0$)
すべての群の分散は等しいです。
残差プロット
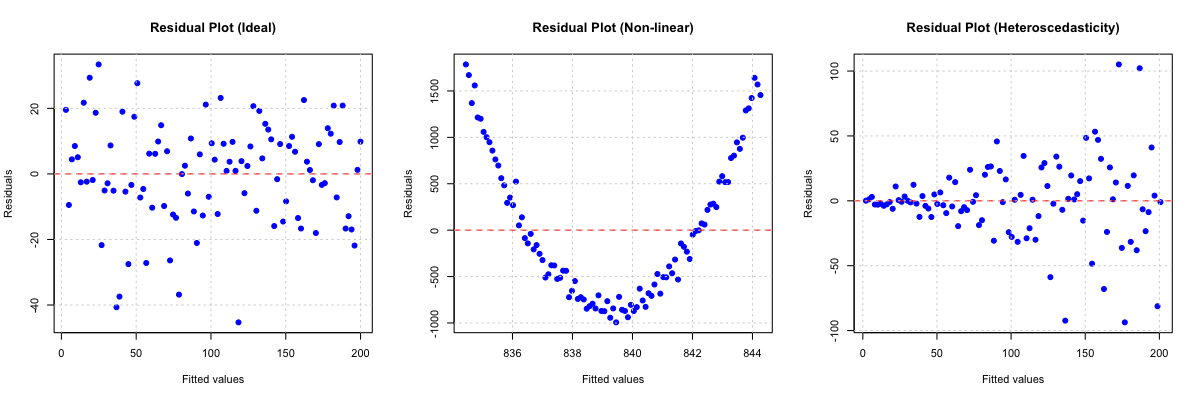
(図:残差プロット)
回帰分析においては、残差(観測値と予測値の差)のプロットが等分散性の診断に用いられます。予測値(または独立変数)を横軸に、残差を縦軸にプロットした際に、点がランダムに均一な帯状に散らばっている場合、等分散性の前提は満たされていると判断できます。逆に、残差のばらつきが予測値の増加とともに広がる場合(ファンネル型)や、特定のパターンを示す場合、等分散性の前提が破られていることを示唆します。
比例ハザード性検定
比例ハザード性(Proportional Hazards Assumption)は、コックス比例ハザードモデル(Cox Proportional Hazards Model)の最も重要な前提条件です。このモデルは、時間依存的な事象(例:患者の死亡、機器の故障)の発生確率を、複数の説明変数を用いて分析する生存時間分析に用いられます。比例ハザード性の前提は、「ある共変量(説明変数)のハザード比が、時間によらず一定である」ことを意味します。
Schoenfeld残差検定(Schoenfeld Residuals Test)
各イベント発生時点における、特定の共変量に対するSchoenfeld残差を計算し、その残差と時間の関係を評価する検定です。Schoenfeld残差は、各共変量のハザード比の変動を反映します。
数式
共変量$j$のSchoenfeld残差$r_{ij}$は、イベントが時間$t_i$で発生した個人について、以下の式で定義されます。
$$r_{ij} = x_{ij} – E(x_j | t_i)$$
ここで、$x_{ij}$はイベント発生個体の共変量$j$の値で、$E(x_j | t_i)$は時間$t_i$におけるリスク集合内の共変量$j$の期待値です。
特徴
この残差を時間に対してプロットし、そのプロットに有意な傾向(例:回帰線が水平ではない)がないかを統計的に検定します。p値が有意水準を下回った場合、比例ハザード性の前提が破られていると判断されます。この検定は、モデル全体の比例ハザード性の検証だけでなく、個々の共変量ごとに検証することも可能です。
帰無仮説 ($H_0$)
ハザード比は時間に依存しません。
層別log-logプロット
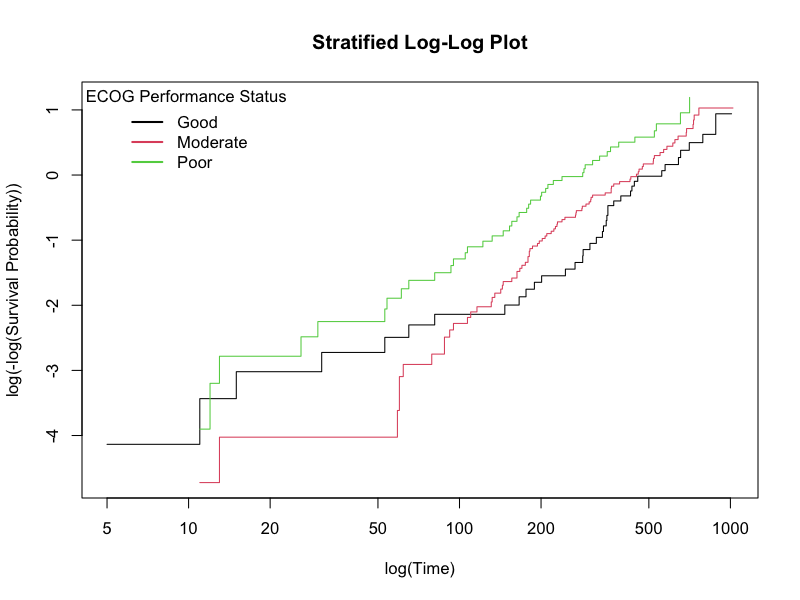
(図:層別log-logプロット)
カテゴリカルな共変量を持つモデルに対して、各カテゴリの累積ハザード関数をログスケールでプロットし、その平行性を確認する視覚的診断手法です。
特徴
もしプロットされた曲線がほぼ平行であれば、比例ハザード性の前提は満たされていると判断できます。曲線が交差したり、互いに離れていったりする場合は、ハザード比が時間に依存していることを示唆します。この手法は、検定結果の解釈を補完し、どの時点で前提が破られるかについての洞察を与えます。
比例ハザード性の違反への対応
比例ハザード性の違反が確認された場合、以下の対策が考えられます。
- 層別コックスモデル(Stratified Cox Model): 比例ハザード性の前提が破られているカテゴリカルな共変量を用いて層化し、各層でハザードを独立に推定します。
- 時間依存性共変量(Time-Dependent Covariates): 共変量と時間の交互作用項をモデルに組み込み、ハザード比が時間とともに変化することをモデル化します。
これらの検定と手法は、統計モデルの信頼性と妥当性を客観的に評価し、分析結果の解釈をより強固なものにするために不可欠です。前提条件の違反が確認された場合は、データの変換、非パラメトリックモデルの使用、またはより複雑なモデルの採用など、適切な対策を講じる必要がございます。
まとめ
これらの検定と手法は、統計モデルの信頼性と妥当性を客観的に評価し、分析結果の解釈をより強固なものにするために不可欠です。前提条件の違反が確認された場合は、データの変換、非パラメトリックモデルの使用、またはより複雑なモデルの採用など、適切な対策を講じる必要がございます。

{kind=link}