
データ分析において「相関関係(Correlation)」を見出すことは、現象の背後にある構造を理解するための重要な第一歩です。しかし、相関関係の存在をもって「一方の変数がもう一方の変数を変化させている」という「因果関係(Causation)」を結論付けることは、統計学における最も典型的かつ致命的な誤りです。
本記事では、相関関係と因果関係の決定的な違いについて、数理的な構造や交絡(Confounding)の概念を交えながら詳細に解説します。観測データから得られた指標をどのように解釈し、実務における意思決定へと応用すべきか、その理論的基盤を構築します。
1. 相関関係と因果関係の定義と構造的差異
まず、相関関係と因果関係の統計学および因果推論における厳密な定義の違いを整理します。
| 概念 | 定義 | 方向性 | 証明の難易度 |
|---|---|---|---|
| 相関関係 | 2つの変数の一方が変化したとき、もう一方も連動して変化する統計的な傾向。 | 対称($X$ と $Y$ の相関は、$Y$ と $X$ の相関と同一) | 容易(観測データから計算可能) |
| 因果関係 | ある変数(原因)の変化が、直接的にもう一方の変数(結果)の変化を引き起こす関係。 | 非対称($X$ が $Y$ を引き起こす場合、$Y$ は $X$ を引き起こさない) | 困難(実験計画や高度な統計的統制が必要) |
「相関関係は因果関係を含意しない(Correlation does not imply causation)」という原則は、データサイエンスにおける鉄則です。観測されたデータ上で変数 $X$ と変数 $Y$ に強い相関が見られた場合、背後には以下の4つのパターンのいずれか、あるいは複合が存在しています。
- 因果関係
$X$ が原因で $Y$ が結果となっている($X \rightarrow Y$)。 - 逆の因果関係
$Y$ が原因で $X$ が結果となっている($Y \rightarrow X$)。 - 交絡(第3の要因)による疑似相関
全く別の変数 $Z$ が、$X$ と $Y$ の両方の原因となっている($X \leftarrow Z \rightarrow Y$)。 - 偶然の一致
サンプルサイズが小さい場合や、時系列データにおいて全く無関係なトレンドが偶然同期した状態。
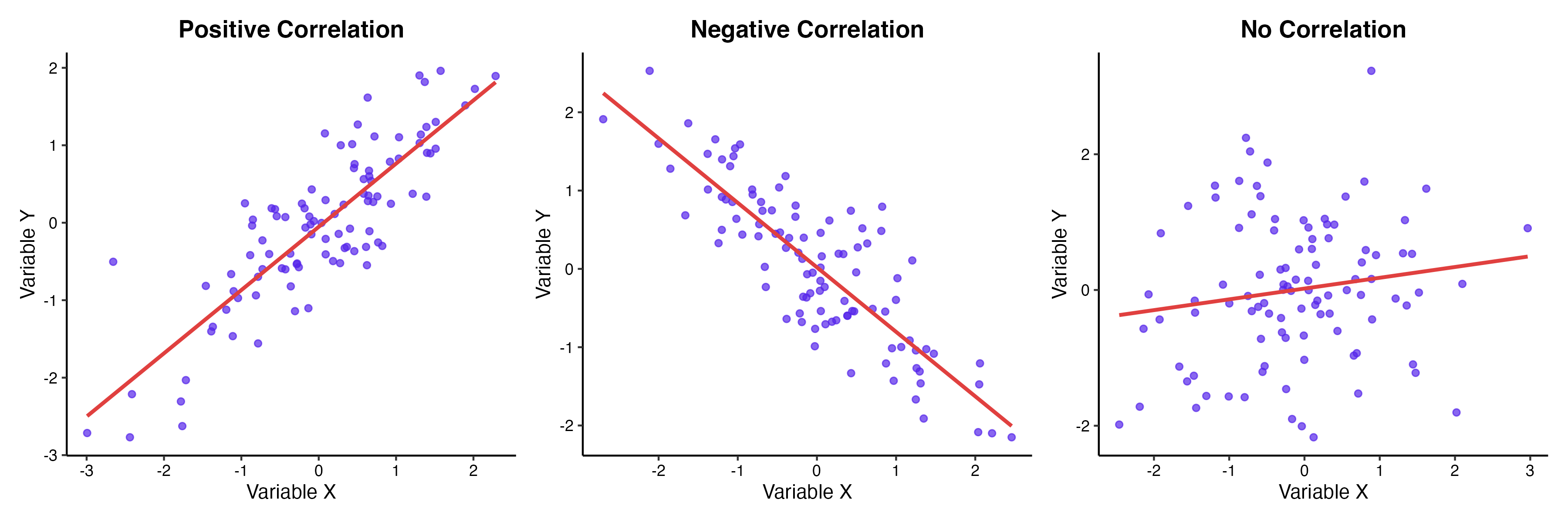
(図1. 相関を生み出す3つの因果構造(有向非巡回グラフ:DAG))
2. 因果関係を成立させるための3条件
ある現象間において因果関係が成立していると見なすためには、一般的に以下の3つの条件(因果の3条件)をすべて満たす必要があります。
- 共変性(Covariation)
原因とされる変数 $X$ と結果とされる変数 $Y$ の間に、統計的に有意な相関関係が存在すること。相関が全く存在しない場合、原則として因果関係も存在しません(ただし、非線形な関係や他の変数が相殺している特殊なケースを除きます)。 - 時間的先行性(Temporal Precedence)
原因とされる変数 $X$ の変化が、結果とされる変数 $Y$ の変化よりも時間的に先に発生していること。結果が原因に先行することは物理法則上あり得ません。 - 他の要因の排除(Elimination of Alternative Explanations)
変数 $X$ と変数 $Y$ の共変性が、$X$ 以外の第3の要因(交絡変数)によって説明できないこと。これを証明することが、データ分析において最も困難な課題となります。
3. 疑似相関と交絡変数のメカニズム
相関関係と因果関係を混同する最大の原因は「疑似相関(Spurious Correlation)」の存在です。疑似相関とは、2つの変数間に直接的な因果関係がないにもかかわらず、共通の原因である「交絡変数(Confounding Variable)」の存在によって、あたかも因果関係があるかのように強い相関が計算されてしまう現象です。
この現象を数理的にモデル化します。観測変数 $X$ と $Y$、および観測されない(あるいは無視されている)交絡変数 $Z$ が存在すると仮定します。各変数の生成過程が以下の線形モデルで表されるとします。
$$
X = \alpha Z + \epsilon_X
$$
$$
Y = \beta Z + \epsilon_Y
$$
ここで、$\alpha$ と $\beta$ はゼロではない係数、$\epsilon_X$ と $\epsilon_Y$ は互いに独立で $Z$ とも独立な誤差項です。このとき、$X$ と $Y$ の間には直接的な因果関係を表すパスは存在しません。しかし、$X$ と $Y$ の共分散 $Cov(X, Y)$ を計算すると以下のようになります。
$$
Cov(X, Y) = Cov(\alpha Z + \epsilon_X, \beta Z + \epsilon_Y) = \alpha \beta Var(Z)
$$
交絡変数 $Z$ の分散 $Var(Z)$ は正の値をとるため、$\alpha$ と $\beta$ が共に正(または共に負)であれば、$Cov(X, Y)$ は正の値を持ちます。結果として、$X$ と $Y$ の間に強い相関係数が算出されることになります。これが疑似相関の数学的な正体です。
最も古典的な具体例として、「アイスクリームの売上($X$)」と「水難事故の件数($Y$)」の相関が挙げられます。この2つの変数をプロットすると強い正の相関関係が現れますが、「アイスクリームを食べたから溺れた」という因果関係は成立しません。背後には「夏の気温($Z$)」という交絡変数が存在し、気温が上昇することでアイスクリームの売上が伸び、同時に海や川で遊ぶ人が増えて水難事故が増加しているに過ぎません。
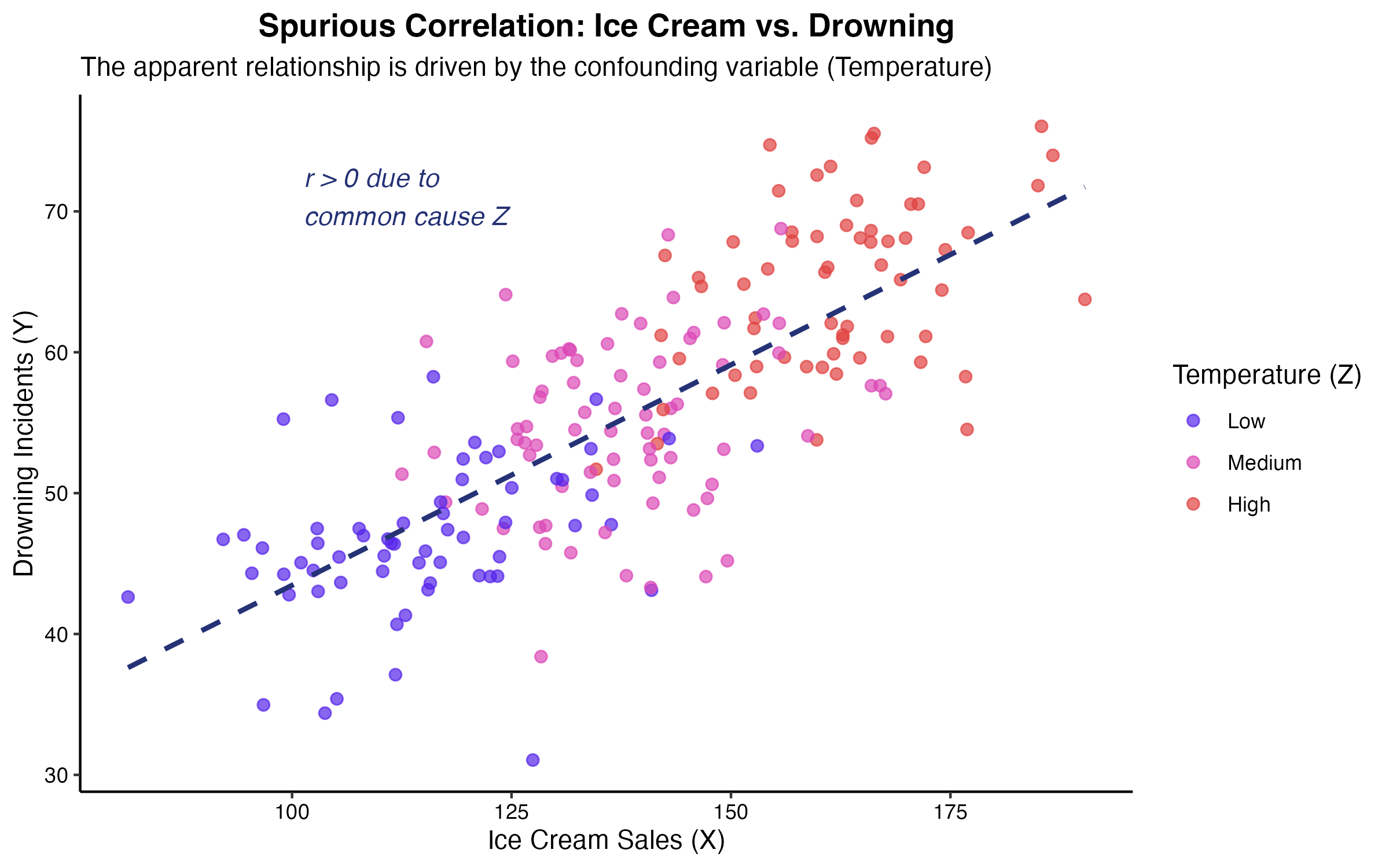
(図2. アイスクリーム売上と水難事故の疑似相関)
4. 偏相関係数による交絡の統制
観測データから疑似相関を排除し、純粋な関係性に近づくための統計的手法の一つが「偏相関係数(Partial Correlation Coefficient)」の算出です。偏相関係数は、交絡変数 $Z$ の影響を数学的に取り除いた(統制した)上で、$X$ と $Y$ の間に残る相関の強さを測定します。
$X$, $Y$, $Z$ の間の単相関係数をそれぞれ $r_{xy}$, $r_{xz}$, $r_{yz}$ としたとき、$Z$ の影響を取り除いた $X$ と $Y$ の偏相関係数 $r_{xy \cdot z}$ は以下の式で定義されます。
$$
r_{xy \cdot z} = \frac{r_{xy} – r_{xz} r_{yz}}{\sqrt{1 – r_{xz}^2} \sqrt{1 – r_{yz}^2}}
$$
先のアイスクリームと水難事故の例において、変数 $Z$(気温)を含めてこの式を適用すると、分子の $(r_{xy} – r_{xz} r_{yz})$ がほぼゼロに近づき、偏相関係数 $r_{xy \cdot z}$ は限りなく $0$(無相関)になります。これにより、2変数間の関係が疑似相関であったことが統計的に証明されます。
5. 潜在結果枠組み(Potential Outcomes Framework)による因果の定義
現代の統計学やデータサイエンスにおいて、因果関係をより厳密に定義・推論するために「ルービン因果モデル(潜在結果枠組み)」が用いられます。
ある対象(ユーザー、患者など)$i$ に対して、原因となる介入(例:新薬の投与、広告の表示)を行う状態を $T=1$、行わない状態(統制状態)を $T=0$ とします。このとき、介入を行った場合の結果を $Y_i^{(1)}$、介入を行わなかった場合の結果を $Y_i^{(0)}$ と定義します。対象 $i$ における純粋な「因果効果(Causal Effect)」は、以下の差分で表されます。
$$
Causal Effect_i = Y_i^{(1)} – Y_i^{(0)}
$$
しかし、現実の世界では、同一の対象に対して同時に「介入した場合」と「介入しなかった場合」の両方を観測することは不可能です(因果推論の根本問題)。観測データから得られる相関関係は、介入を受けた集団の平均と、介入を受けなかった別集団の平均の差に過ぎません。この2つの集団の背後にある性質(交絡変数)が異なる場合、相関と因果は大きく乖離します。
6. 【実務事例】ビジネスや研究における因果推論の重要性
相関と因果の混同を避け、正しい意思決定を行うための具体的な適用事例を2つ紹介します。
6.1. Eコマースにおけるメールマガジンの効果測定(マーケティング)
背景
あるECサイトのマーケティング部門が、「メールマガジンの購読」と「年間購入金額」の間に強い正の相関があることを発見しました。このデータに基づき、経営層は「すべてのユーザーに強制的にメールマガジンを配信すれば、売上が飛躍的に向上する」という仮説を立てました。
分析と問題点
この仮説は典型的な疑似相関の罠に陥っています。ここには「ブランドに対するロイヤルティ(関与度)」という交絡変数が潜んでいます。ブランドへの関心が高いユーザーだからこそ、自発的にメールマガジンを購読し、同時に多くの商品を購入しているに過ぎません。強制的にメールを配信しても、関与度の低いユーザーの購買意欲が引き上げられるとは限らず、逆にスパムと見なされて退会率(チャーン)を悪化させるリスクがあります。
解決策
因果効果を正確に測定するためには、A/Bテスト(ランダム化比較試験:RCT)を実施する必要があります。対象ユーザーをランダムに2群に分け、一方にはメールを配信し(介入群)、もう一方には配信しない(統制群)という実験デザインを組むことで、初めて「メール配信が売上を向上させる」という因果関係の有無を定量的に評価できます。
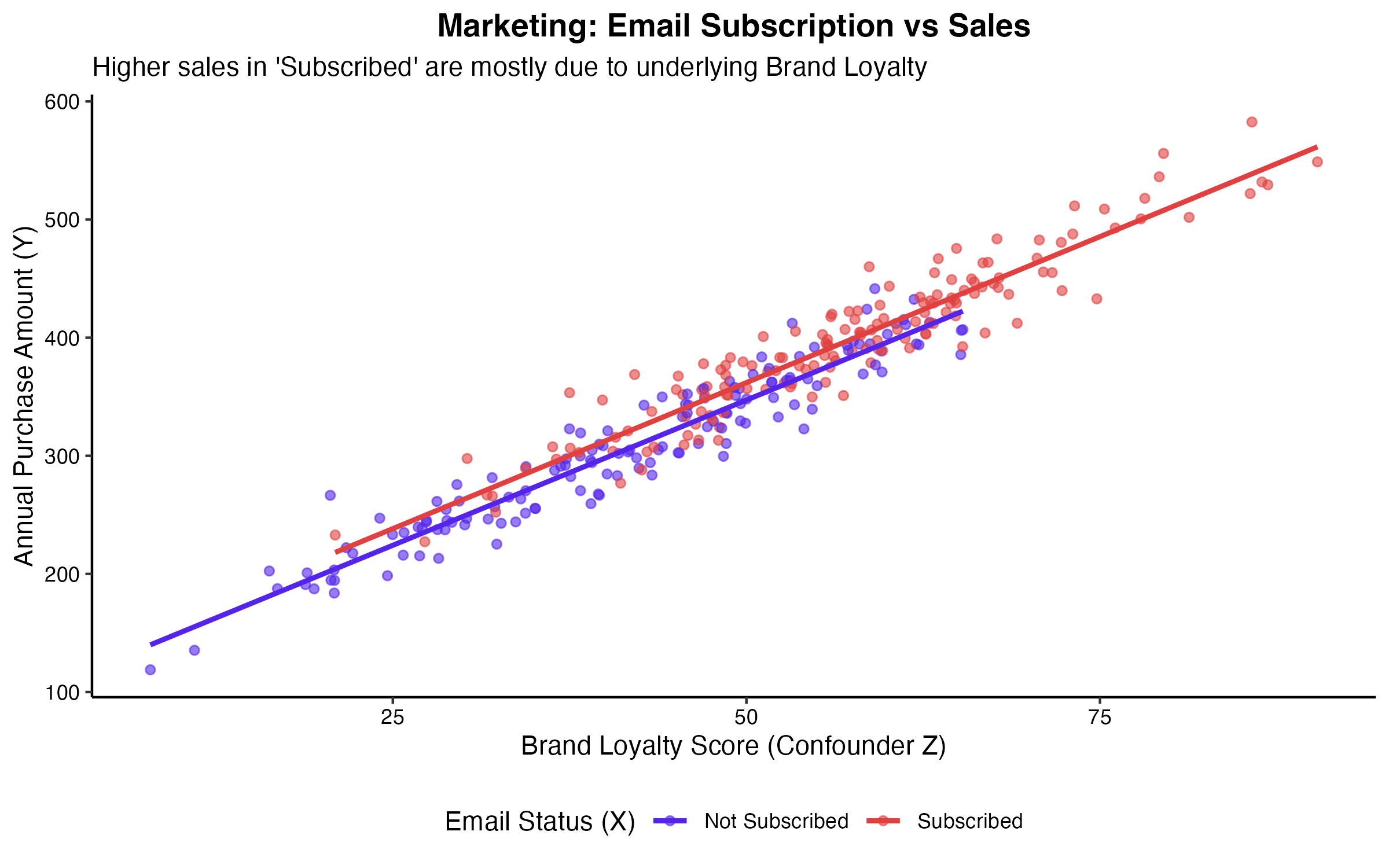
(図3. マーケティングにおける交絡(ブランドロイヤルティの影響))
6.2. 観察研究における医療データの評価(ヘルスケア)
背景
過去の疫学的な観察研究において、「ホルモン補充療法(HRT)を受けている女性は、受けていない女性に比べて冠動脈疾患の発症率が低い」という強い負の相関が報告され、予防効果がある(因果関係がある)と広く信じられていました。
分析と問題点
後の大規模なランダム化比較試験によって、HRTには冠動脈疾患の予防効果はなく、むしろリスクをわずかに上昇させる可能性があることが判明しました。初期の観察研究で相関が出た理由は、「健康意識や社会経済的地位」という交絡変数の存在です。HRTを自発的に受ける女性は、日常的に運動を行い、健康的な食生活を送り、質の高い医療アクセスを持つ傾向が高く、その結果として心疾患リスクが低かっただけでした。
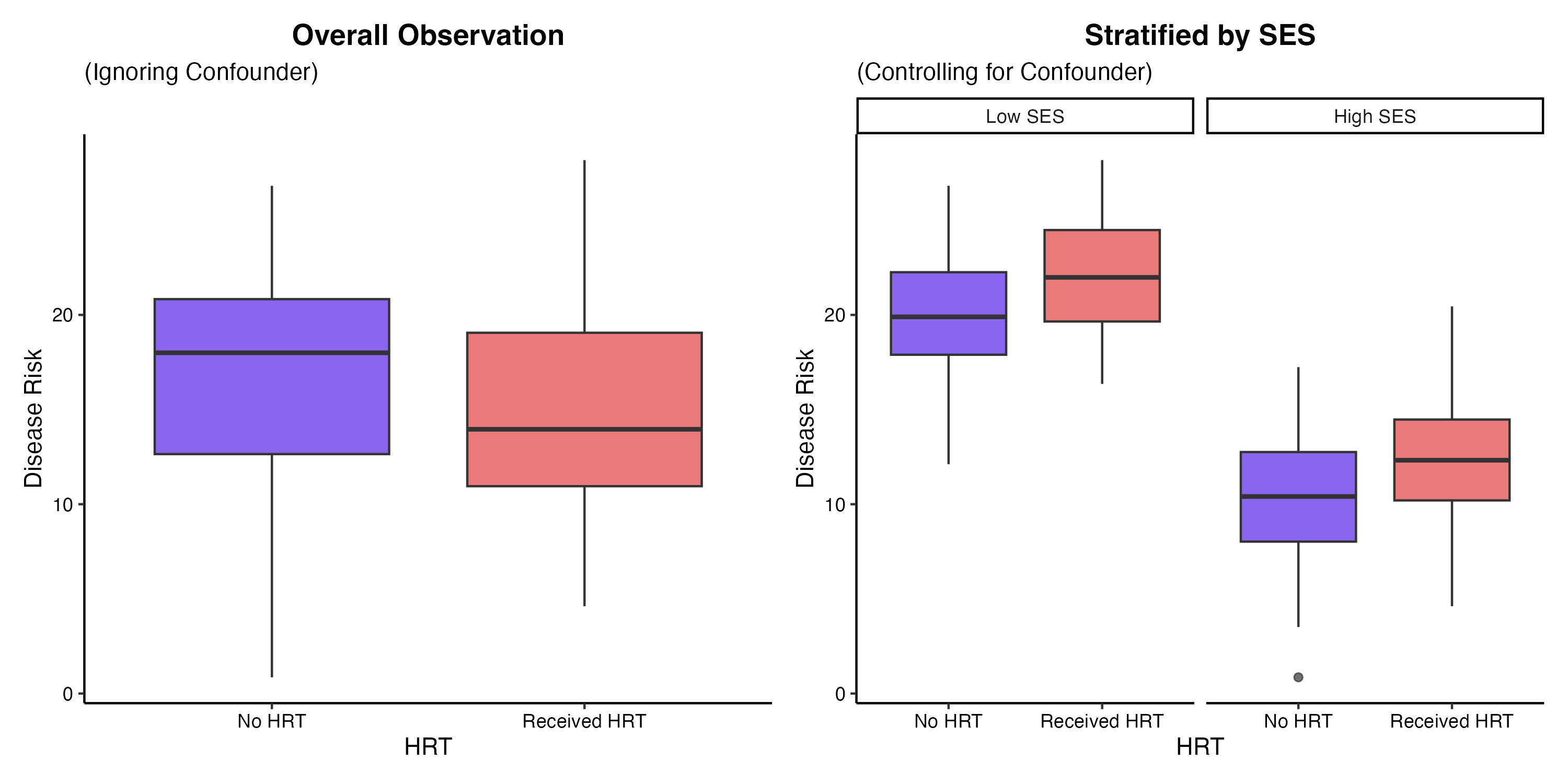
(図4. 医療データにおける交絡変数(シンプソンのパラドックス))
まとめ
相関分析はデータの傾向を掴むための強力な探索的ツールですが、「相関関係=因果関係」と短絡的に結びつけることは、ビジネス上の投資損失や誤った科学的結論につながる危険性を孕んでいます。
データサイエンスの実務においては、算出された相関係数に満足するのではなく、「時間的先行性は担保されているか」「第3の要因(交絡変数)は存在しないか」という批判的思考(クリティカル・シンキング)を常に持つことが求められます。相関を入り口として仮説を構築し、偏相関分析、重回帰分析、傾向スコアマッチング、あるいはA/Bテストといった高度な因果推論の手法へとステップアップしていくことが、データ分析から真の価値を引き出すための正しいプロセスです。

{kind=link}