探索的データ分析(EDA)は、仮説の検証に先立ち、データの全体像、隠されたパターン、異常値、および変数間の関係性を視覚的に捉えるための統計手法群です。数値的な要約統計量だけでは見過ごされがちなデータの複雑な特性を、グラフや図を用いて直感的に理解することが、EDAの主要な目的です。EDAは、単なるグラフ作成を超え、データサイエンスプロジェクト全体の成功を左右する、反復的かつ不可欠なプロセスです。
分布の可視化
データの分布を理解することは、その後の分析の前提条件を評価する上で不可欠です。ここでは、単一の変数の分布を可視化する代表的な手法を解説します。
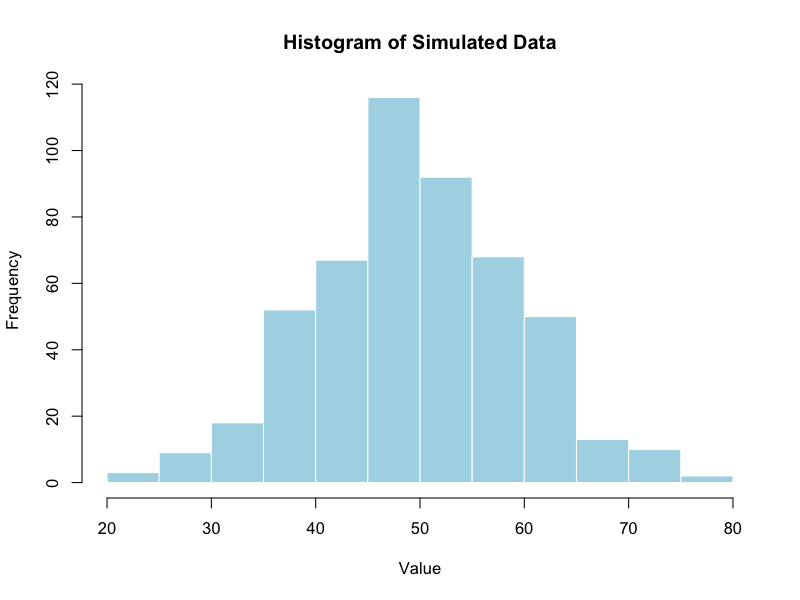
ヒストグラム(Histogram)
(図:ヒストグラム)
ヒストグラムは、量的データの度数分布を棒グラフで表現する手法です。データの値域をいくつかの区間(ビン)に分割し、各区間に含まれる観測値の数を棒の高さで示します。
目的
データの中心、ばらつき、歪度、尖度、および多峰性を視覚的に把握します。
利用法
ビンの幅を変えることで、分布の粗密な構造を詳細に観察できます。ビンの幅が広すぎると細かな分布の構造が見えなくなり、狭すぎるとノイズが多くなります。適切なビンの幅は、データの特性と分析の目的に応じて決定されます。ヒストグラムは、データの分布が正規分布に近いか、あるいは歪んでいるかといった予備的な情報を得る上で最も基本的なツールです。
特に、歪度(Skewness)や尖度(Kurtosis)といった分布の形状を直感的に評価するのに役立ちます。また、分布が単一のピーク(単峰性)を持つか、あるいは複数のピーク(多峰性)を持つかを確認することは、データに複数の潜在的なグループが存在することを示唆し、その後のクラスタリング分析などの方向性を定める手がかりとなります。
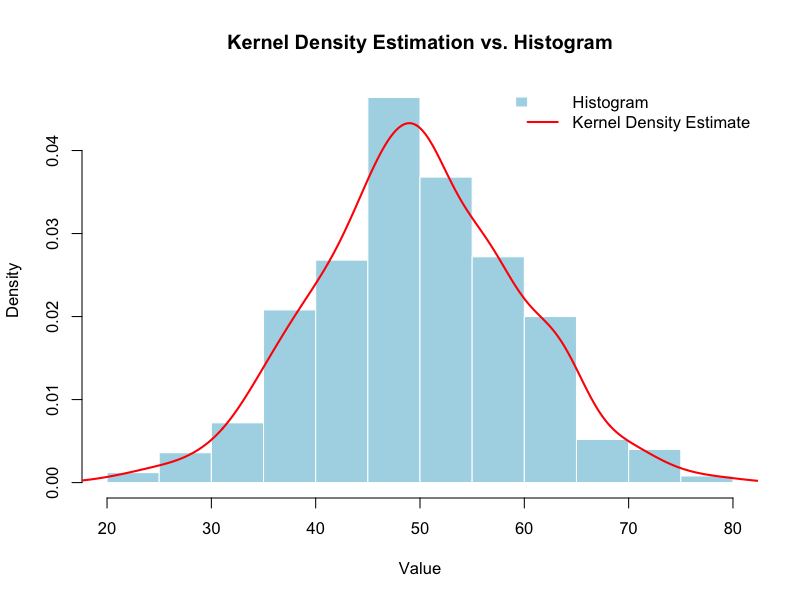
カーネル密度推定(Kernel Density Estimation, KDE)
(図:カーネル密度推定)
KDEは、ヒストグラムをより滑らかにしたもので、データの背後にある連続的な確率密度関数を推定する非パラメトリック手法です。各観測値を中心にカーネル関数(通常は正規分布)を配置し、それらを合計することで平滑化された分布曲線を作成します。
目的
ヒストグラムのビンの幅に依存せず、データの分布の形状をより正確かつ滑らかに可視化します。
利用法
分布のピーク(最頻値)や裾の形状を視覚的に捉えるのに特に有効です。KDEの滑らかさは、使用するカーネル関数と帯域幅(bandwidth)に依存します。帯域幅が広すぎると分布の細部が失われ、狭すぎるとノイズが強調されます。KDEは、データの基礎となる連続的な分布を視覚的に推測するのに優れており、特に多峰性の存在をヒストグラムよりも明確に示せる場合があります。
幹葉表示(Stem-and-Leaf Plot)

(図:幹葉表示)
幹葉表示は、ヒストグラムの機能に加えて、個々のデータ点の値を同時に表示できる手法です。データを「幹」(上位の桁)と「葉」(下位の桁)に分けて表現します。
目的
データの分布の形状を把握すると同時に、個々の観測値を保持します。
利用法
比較的データ数が少ない場合に有用で、外れ値の特定も容易です。ヒストグラムがデータ量の多い場合に有効であるのに対し、幹葉表示はデータセットの細かな構造を維持しつつ、分布の全体像を把握したい場合に適しています。データの正確な値を知りたいという学術的な文脈で、特に役立ちます。
変数間の関係の可視化
複数の変数間の関係性を分析することは、因果関係や相関関係の仮説を立てる上で重要です。
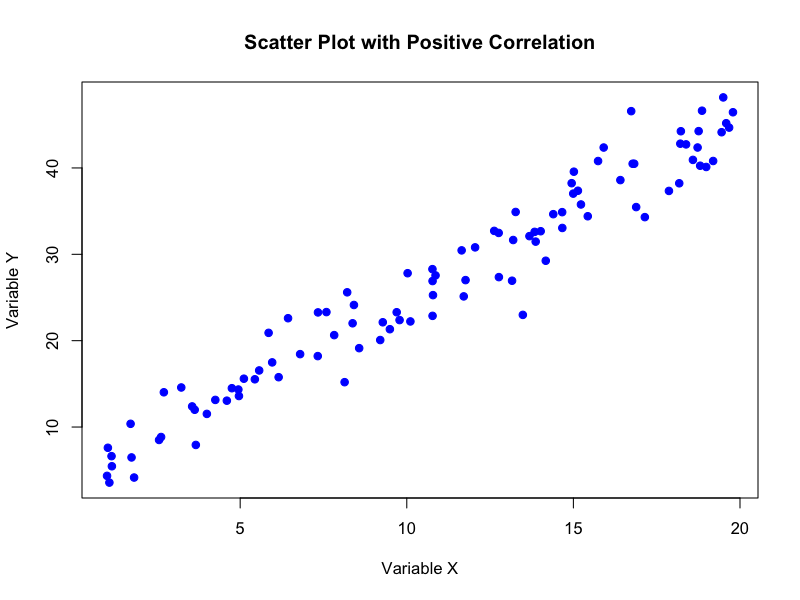
散布図(Scatter Plot)
(図:散布図)
散布図は、2つの量的変数の関係を、デカルト座標上にプロットされた点の集合として可視化する手法です。
目的
2変数間の相関の方向性(正の相関、負の相関、無相関)や、線形性、非線形性、および外れ値やデータクラスターの存在を視覚的に検出します。
利用法
回帰分析に先立ち、変数間の関係の性質を探索する際に広く用いられます。点の集合が右肩上がりの傾向にあれば正の相関、右肩下がりであれば負の相関が示唆されます。点がランダムに散らばっている場合は無相関である可能性が高いです。
また、散布図は外れ値(他の点から大きく離れた点)や、データが複数のクラスターを形成しているかどうかを視覚的に特定するのに非常に効果的です。特に、線形回帰モデルの前提条件である線形性の確認にも利用されます。
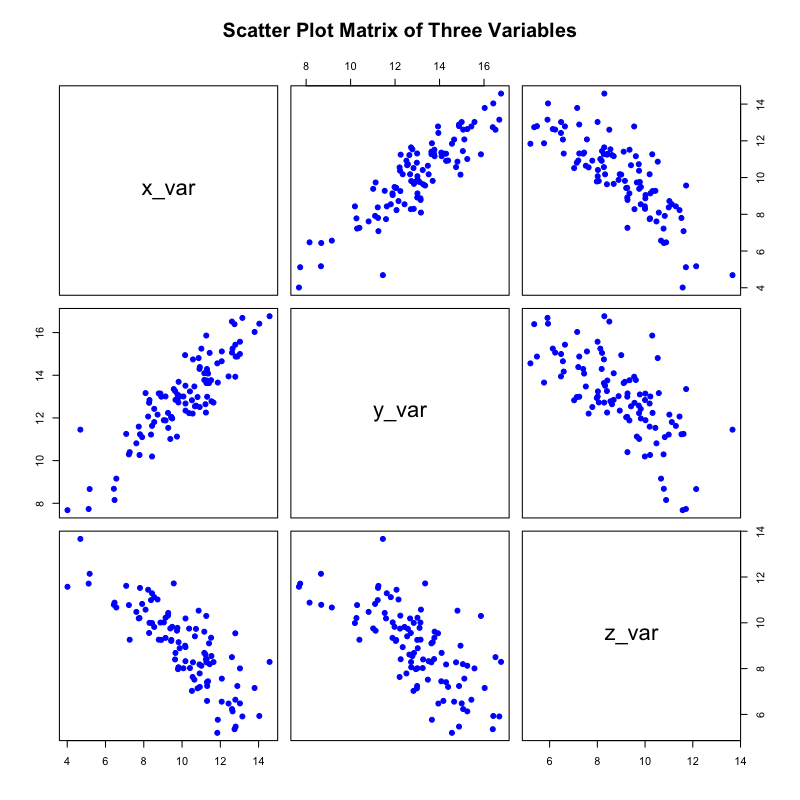
散布図行列(Scatter Plot Matrix)
(図:散布図行列)
散布図行列は、3つ以上の量的変数が存在する場合に、それらのすべての組み合わせの散布図を一覧表示する手法です。
目的
複数の変数間のすべてのペアワイズな関係性を一度に俯瞰し、複雑なデータセットの構造を効率的に探索します。
利用法
大規模なデータセットにおいて、どの変数間に相関関係が存在し、さらなる分析が必要かを素早く特定できます。対角線上にはヒストグラムやKDEを配置することが多く、これにより単一の変数の分布情報も同時に得ることができます。
要約とグループ比較
要約統計量や視覚化手法を組み合わせて、データの主要な特性を把握し、異なるグループ間の比較を行います。
箱ひげ図(Box Plot)
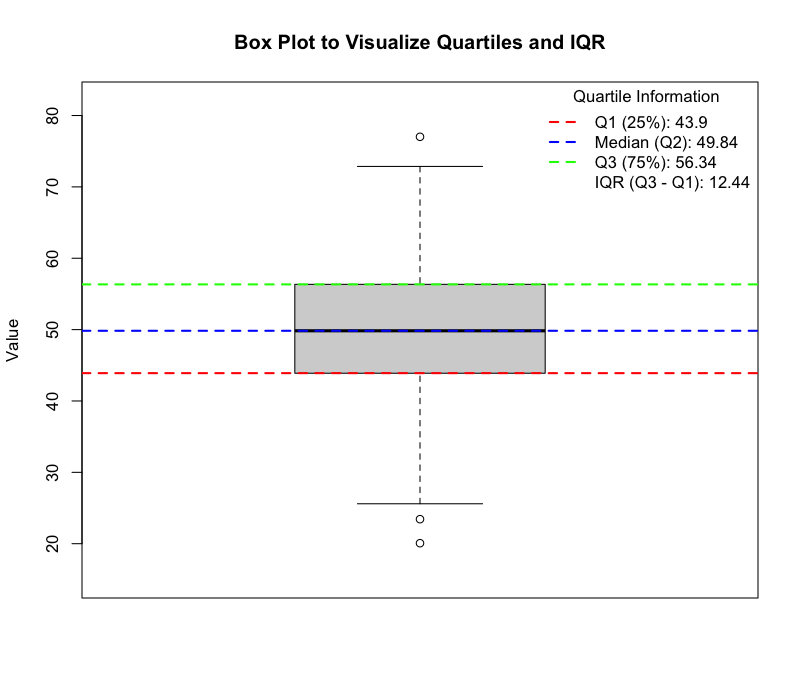
(図:箱ひげ図)
箱ひげ図は、データの分布を視覚的に要約する手法です。中央値(箱の中央の線)、第1四分位数(箱の下端)、第3四分位数(箱の上端)、四分位範囲(箱の高さ)、および外れ値を明確に表示します。
目的
複数のデータセットやグループ間の分布を比較する際に非常に有用です。中央値の比較、ばらつきの差、歪みの有無、および外れ値の存在を一度に確認できます。
利用法
データが正規分布に従うかどうかの予備的な評価にも役立ちます。箱ひげ図は、データの要約に優れている反面、ヒストグラムやKDEのようにデータの詳細な分布形状(例:多峰性)を捉えることはできません。このため、バイオリンプロット(Violin Plot)のように、箱ひげ図にKDEの要素を組み合わせた可視化手法も多く用いられます。
バーチャート(Bar Chart of Means)

(図:バーチャート)
バーチャートは、複数のカテゴリグループの平均値を棒の高さで比較する手法です。
目的
カテゴリ変数と量的変数間の関係性を視覚化し、各グループの代表値を比較します。
利用法
平均値に加えて、エラーバー(標準誤差や標準偏差)を追加することで、平均値の推定の不確実性や、グループ間の平均値の差が統計的に有意であるかを予備的に判断する手助けとなります。エラーバーが重なり合う場合は、統計的に有意な差がない可能性が高いことを示唆します。
多次元データの可視化
今日のデータセットはしばしば多数の変数を持ち、2次元や3次元の散布図では可視化が困難です。このような高次元データを扱うための探索的データ分析手法も重要です。
主成分分析(Principal Component Analysis, PCA)
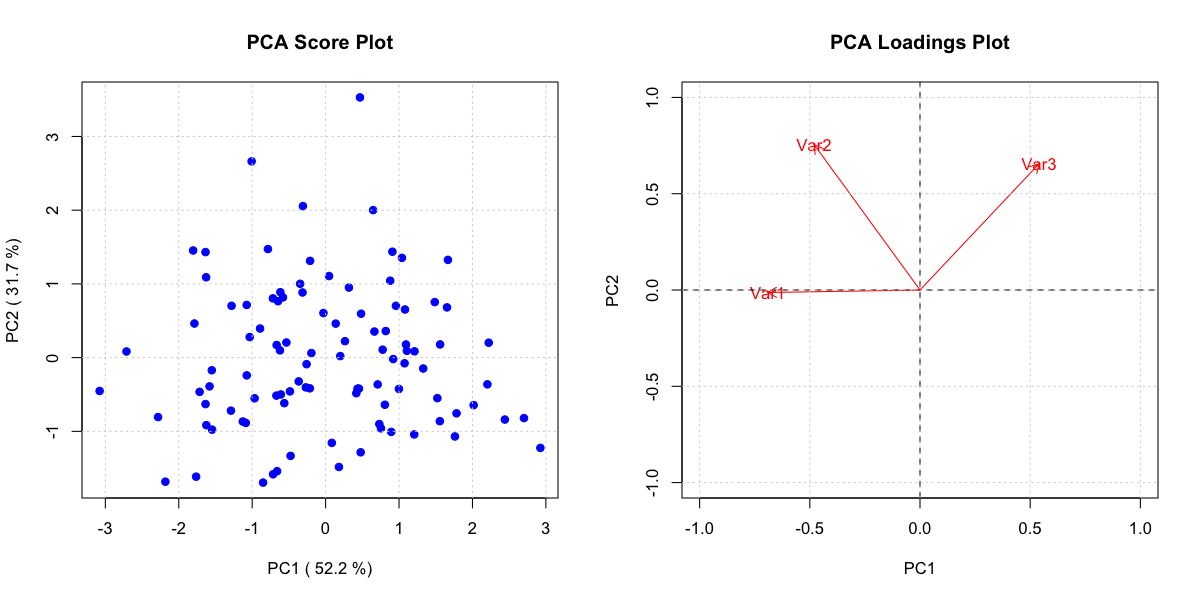
(図:主成分分析)
PCAは、データのばらつきが最も大きい方向(主成分)を見つけ出すことで、高次元データを低次元(通常は2次元または3次元)に圧縮する手法です。
目的
多数の相関を持つ変数から、より少ない数の非相関な変数(主成分)を抽出し、データの構造を可視化します。
利用法
PCAの第1主成分と第2主成分を軸とした散布図を作成することで、高次元データ内に存在するクラスターや傾向を視覚的に発見できます。これは、データセット全体の構造を俯瞰するのに非常に効果的です。
t-SNE(t-Distributed Stochastic Neighbor Embedding)
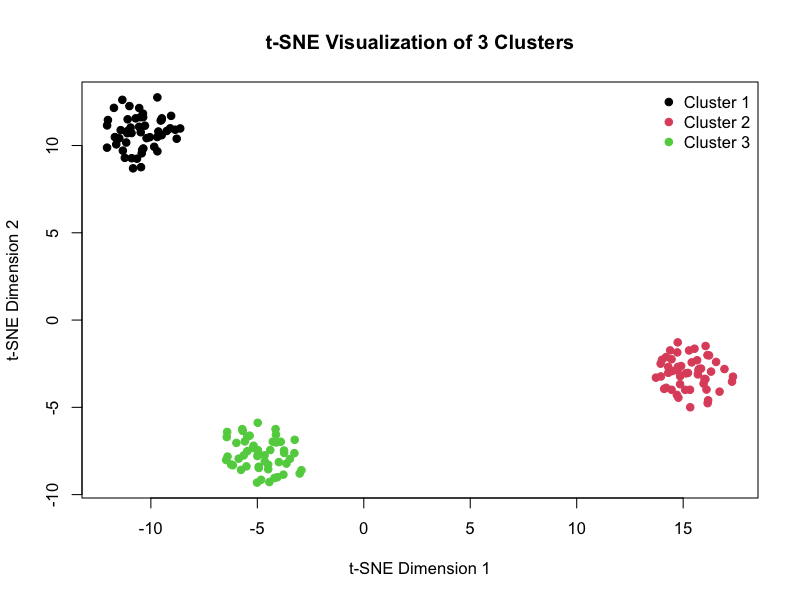
(図:t-SNE)
t-SNEは、高次元空間におけるデータの類似度を保ちながら、データを2次元または3次元に非線形的に次元削減する手法です。
目的
特にクラスター構造を持つ高次元データを、視覚的に分かりやすい形で低次元空間にマッピングします。
利用法
t-SNEによって生成された散布図は、データセット内の隠れたクラスターやグループを明確に示します。PCAとは異なり、局所的な構造を維持することに優れているため、複雑なデータセットのクラスター分析の予備段階で広く用いられます。
EDAのプロセスと実践
EDAは単発の作業ではなく、以下のサイクルを繰り返すプロセスです。
- データクリーニングと前処理:欠損値の処理、データ型の変換、外れ値の特定と対応を行います。
- 単変量分析:ヒストグラムや箱ひげ図を用いて、各変数の分布を個別に理解します。
- 多変量分析:散布図や相関行列を用いて、変数間の関係性を探索します。
- 結果の解釈と反復:可視化の結果から新たな仮説を立て、さらに詳細な分析や別の可視化手法を試行します。
この反復的なサイクルを通じて、アナリストはデータに対する直感を養い、仮説構築を洗練させ、最終的な統計モデルの選択と構築をより強固なものにします。
まとめ
探索的データ分析は、単にグラフを作成することを超え、データに対する深い洞察を得るための反復的なプロセスです。これらの手法を適切に用いることで、統計モデルの選択や仮説の策定をより確実なものにすることができます。


{kind=link}