
前項で解説したスピアマンの順位相関係数と同様に、データが正規分布に従うという仮定を満たさない場合(非正規性)や、極端な外れ値が含まれる場合、あるいはデータ自体が順位(順序尺度)で与えられている場合に適用されるノンパラメトリックな指標として「ケンドールの順位相関係数(Kendall’s rank correlation coefficient)」が存在します。通常、ギリシャ文字の $\tau$(タウ)を用いて表されます。
スピアマンの手法が「順位に変換した値に対するピアソンの積率相関係数」という構造を持つのに対し、ケンドールの手法はデータペア間の「大小関係の整合性(確率)」に直接着目して計算されるという数理的な違いがあります。この性質により、特にサンプルサイズが小さいデータセットにおいて、より妥当性の高い統計的推論を提供します。
数理的メカニズムと計算手順
ケンドールの順位相関係数は、任意の2つのデータペアを取り出した際に、それらの大小関係が2つの変数間で一致しているか(順方向)、反転しているか(逆方向)を全ペアについてカウントすることで算出されます。
サンプルサイズを $n$ とし、観測されたデータペアの集合を $(x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)$ とします。この中から任意の2つのペア $(x_i, y_i)$ と $(x_j, y_j)$ (ただし $i < j$)を取り出したとき、以下の条件に従ってペアを分類します。
- 順方向ペア(Concordant pair)
$x$ の大小関係と $y$ の大小関係が一致している状態です。数式では $(x_i – x_j)(y_i – y_j) > 0$ と定義されます。 - 逆方向ペア(Discordant pair)
$x$ の大小関係と $y$ の大小関係が反転している状態です。数式では $(x_i – x_j)(y_i – y_j) < 0$ と定義されます。 - 同順位(Tie)
$x_i = x_j$ または $y_i = y_j$ となり、大小関係が判定できない状態です。
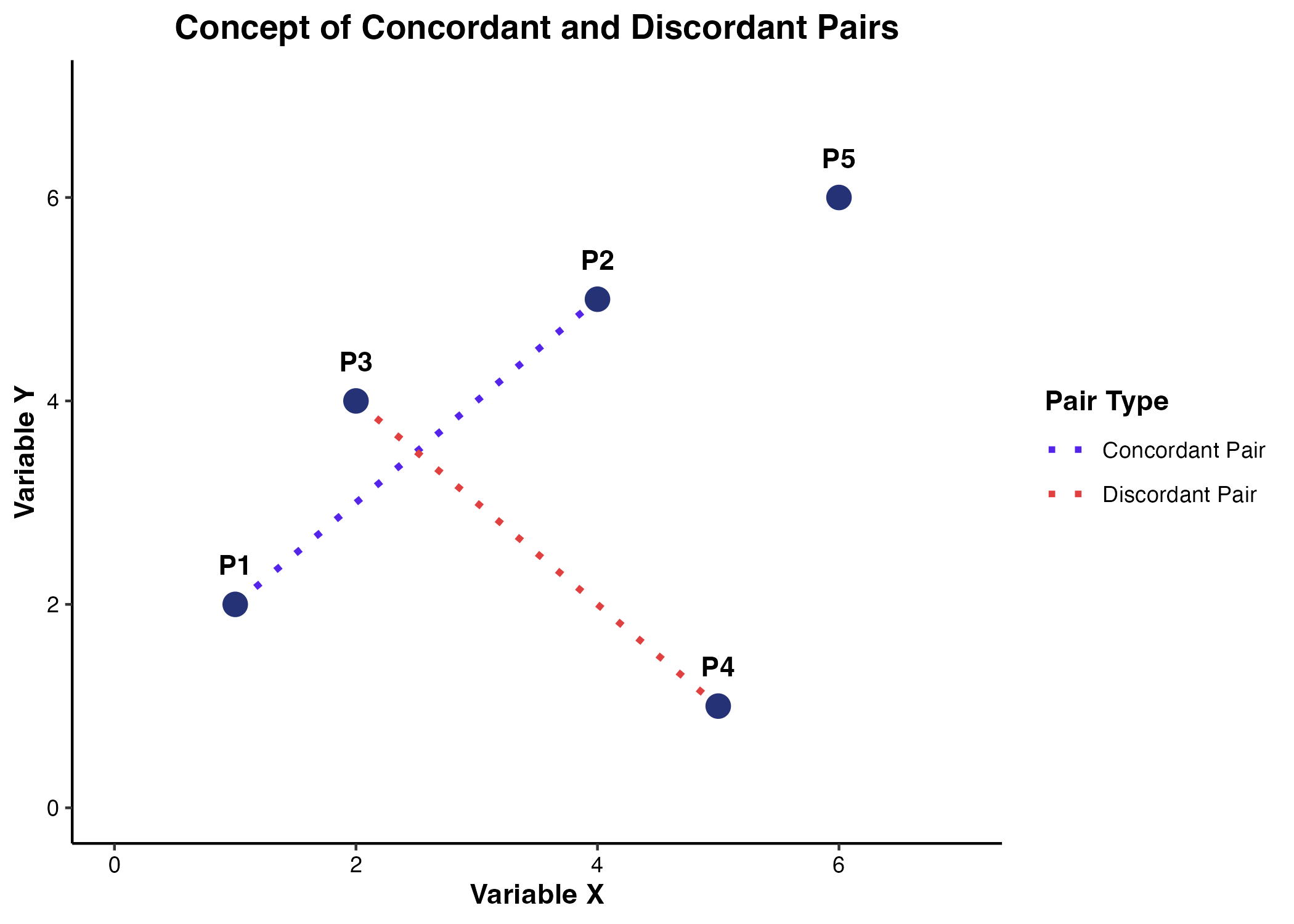
(図1. 順方向ペアと逆方向ペアの概念図)
同順位(タイ)が存在しないと仮定した場合の基本的なケンドールの順位相関係数($\tau_a$ と呼ばれます)は、順方向ペアの総数 $C$ と逆方向ペアの総数 $D$ を用い、全ペアの組み合わせ数 $\frac{n(n-1)}{2}$ で割ることで、以下の式のように定義されます。
$$
\tau_a = \frac{C – D}{\frac{n(n-1)}{2}}
$$
この指標はピアソンの積率相関係数と同様に $-1 \leq \tau \leq 1$ の範囲をとります。すべてのペアが順方向であれば $\tau = 1$、すべてが逆方向であれば $\tau = -1$、順方向と逆方向の数が等しければ $\tau = 0$ となります。
実務のデータでは同じ値(同順位)が発生することが一般的です。同順位の存在を数学的に補正した計算式として $\tau_b$(タウ・ビー)が用いられます。変数 $X$ のみで同順位となるペア数を $T_x$、変数 $Y$ のみで同順位となるペア数を $T_y$ としたとき、$\tau_b$ は以下の式で算出されます。
$$
\tau_b = \frac{C – D}{\sqrt{(C + D + T_x)(C + D + T_y)}}
$$
スピアマンの順位相関係数との比較と使い分け
ノンパラメトリックな相関指標として、スピアマンの $\rho$ とケンドールの $\tau$ のどちらを選択すべきかという問題は、データサイエンスの実務において頻出します。以下の表に両者の数理的特性と適用基準を整理します。
| 比較項目 | ケンドールの順位相関係数($\tau$) | スピアマンの順位相関係数($\rho$) |
|---|---|---|
| 指標の解釈 | 「ランダムに抽出したペアの大小関係が一致する確率」と「反転する確率」の差という、確率論的な解釈が直接可能。 | 順位付けされたデータに対する「分散の共有度合い」を示す(ピアソンの $r$ のノンパラメトリック版)。 |
| サンプルサイズの影響 | サンプルサイズが小さい(例:$n < 30$)場合でも、母集団のパラメータに対する推定量として偏りが小さく、p値の計算がより正確。 | サンプルサイズが十分に大きい場合に適する。小さい場合は誤差が大きくなりやすい。 |
| 外れ値に対する頑健性 | 極めて高い。順位の「差の大きさ」を一切考慮せず、大小の「方向」のみを見るため、順位の変動に強い。 | 高いが、順位の「差の二乗」を計算に用いるため、順位の極端な変動にはケンドールより影響を受けやすい。 |
| 計算量 | すべてのペアの組み合わせを比較するため、計算量は $O(n^2)$ となり、大規模データでは処理負荷が高い。 | 順位のソートと差の計算のみで済むため、計算量は $O(n \log n)$ となり、大規模データでも高速。 |
原則として、データ数が少なく($n$ が十数個程度)、外れ値の存在が懸念される信頼性試験などの小規模実験データにはケンドールの $\tau$ を、Webアクセスログなどの大規模な順序データには計算効率の観点からスピアマンの $\rho$ を適用するのが統計学的なセオリーです。
実務事例:製造業における耐久試験の順位評価
サンプルサイズが極度に制約される環境下において、ケンドールの順位相関係数がどのように適用されるか、製造業の品質保証プロセスを例に解説します。
背景
ある航空機部品メーカーにおいて、新素材を用いたタービンブレードの耐久性評価を実施しています。耐久試験はコストと時間の制約上、12個のサンプル($n=12$)に対してのみ実施されました。専門家の目視検査による「表面劣化の深刻度順位(1位〜12位)」と、センサーから得られた「微小振動の振幅データの順位(1位〜12位)」の間に相関があるかを確認し、目視検査をセンサーによる自動評価に代替できるかを検証します。
分析アプローチ
サンプル数が $n=12$ と非常に小さく、かつデータが順序尺度であるため、ピアソンの相関係数は適用できません。また、サンプルサイズの小ささからスピアマンの $\rho$ では検定の精度が担保されないと判断し、ケンドールの $\tau_b$ を用いて相関分析を実施しました。
解釈と意思決定
計算の結果、$\tau_b = 0.81$ という強い正の相関が確認され、統計的仮説検定においても有意水準 1% で帰無仮説(無相関)が棄却されました。$\tau_b = 0.81$ という数値は、任意の2つの部品を抽出した際、「目視で劣化が激しいと判定された部品が、センサーデータでもより劣化していると判定される確率」が非常に高いことを数理的に意味しています。この確率論的根拠に基づき、品質保証部門は目視検査からセンサー自動評価への移行プロセスを承認しました。
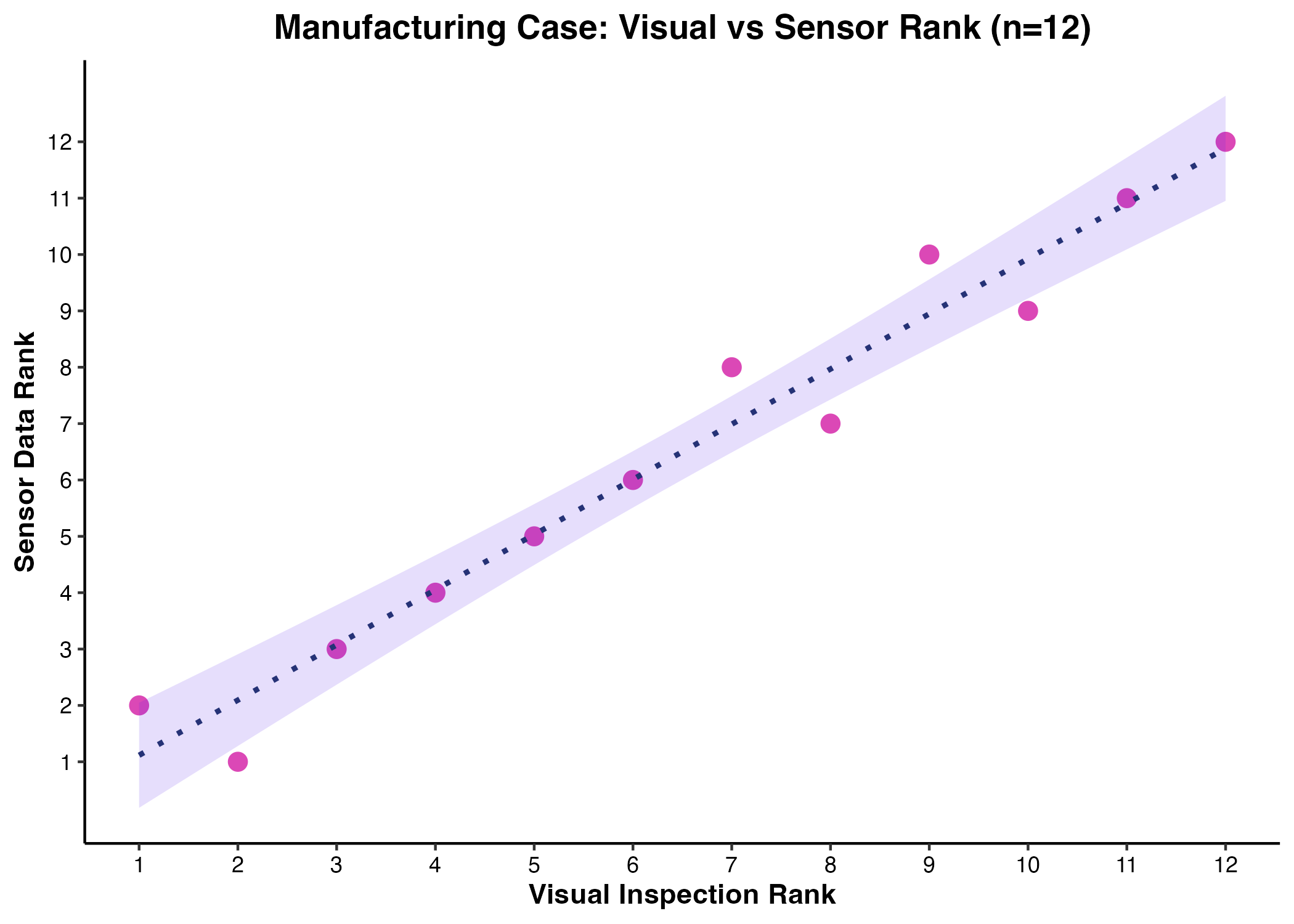
(図2. 耐久試験における目視順位とセンサー順位の相関)

{kind=link}