
相関分析は、単に相関係数を算出するだけの手続きではありません。得られた数値が意味を持つためには、データの性質を正しく見極め、適切な前処理を行い、統計的な裏付けを確認する体系的な手順が不可欠です。適切なプロセスを経ない分析は、外れ値による数値の歪みや、非線形な関係性の見落としを招き、組織の意思決定を誤らせるリスクを孕んでいます。
本項では、実務における相関分析の標準的なフローを、準備段階から結果の解釈、そして事後検証まで詳細に解説します。データサイエンスの現場で求められる、再現性と客観性を担保するための構造的なアプローチを提示します。
相関分析の標準的な実行フロー
相関分析を遂行するにあたり、遵守すべき基本的なステップを以下の表に整理します。各工程は独立しているのではなく、相互に関連し合っている点に留意が必要です。
| ステップ | 実施内容 | 主な確認事項・成果物 |
|---|---|---|
| 1. 分析目的の定義 | 関連性を調べたい2つの変数を選択し、仮説を立てる。 | ドメイン知識に基づく変数の選定、期待される相関の向き。 |
| 2. データの型の確認 | 変数の尺度(名義・順序・間隔・比率)を確認する。 | 連続変数か、あるいは順位データか(手法の選択に直結)。 |
| 3. データクレンジング | 欠損値や異常値の処理、データの正規性を確認する。 | ヒストグラムによる分布確認、外れ値の特定。 |
| 4. 視覚化(散布図) | 計算に先立ち、散布図を作成してデータの形状を把握する。 | 直線性の有無、クラスターの形成、外れ値の視覚的確認。 |
| 5. 相関係数の算出 | データの性質に適した相関係数を選択し、数値を算出する。 | ピアソン、スピアマン、ケンドール等の適切な選択。 |
| 6. 有意性の検定 | 算出された相関が統計的に有意であるかを確認する。 | p値の評価、信頼区間の算出、サンプルサイズの影響考慮。 |
| 7. 解釈と事後検証 | 因果関係の有無、疑似相関の可能性を検討する。 | 交絡変数の探索、偏相関分析の検討。 |
1. 前処理とデータの特性把握
相関係数の計算を行う前に、データの質を担保するための「前処理」が必要です。統計学的に妥当な推論を行うためには、以下の3点について厳密に評価しなければなりません。
データの尺度と手法の整合性
分析対象となる変数がどのような尺度を持っているかによって、採用すべき手法が決まります。間隔尺度や比率尺度であり、かつ正規分布に従う場合は「ピアソンの積率相関係数」を適用しますが、アンケートの満足度のような順序尺度の場合は「スピアマンの順位相関係数」や「ケンドールの順位相関係数」を選択するのが定石です。誤った尺度の適用は、相関係数の過大または過小評価を引き起こします。
外れ値の検出と取り扱い
ピアソンの相関係数は、平均値からの偏差の積を利用するため、極端な値(外れ値)に対して極めて敏感です。1点でも異常なデータが存在すると、全体の相関関係が塗り替えられてしまう可能性があります。外れ値を発見した際は、それが測定ミスなどのエラーであれば除外を検討し、正当なデータである場合は外れ値の影響を受けにくいノンパラメトリックな手法(スピアマンなど)への変更を検討します。
正規性の確認
ピアソンの相関係数が理論的に正しく機能するための前提条件の一つに、2変数が「2変量正規分布」に従うことが挙げられます。分布が大きく歪んでいる(例:裾が長い分布)場合、対数変換などの変数変換を行い、分布を正規分布に近づけてから相関係数を算出する、あるいは分布の形状に依存しない手法を選択する判断が求められます。
2. 視覚的確認(散布図)の徹底
統計数値を算出する前に、必ず散布図を用いてデータの全体像を直視する必要があります。これは「アンスコムの例(Anscombe’s quartet)」に代表されるように、相関係数や平均、分散といった要約統計量が全く同じであっても、実際のデータの分布が劇的に異なるケースが存在するためです。
- 線形性の確認
相関分析は基本的に「直線的な関係」を前提とします。散布図上でデータが曲線状(U字型やS字型)に分布している場合、相関係数が低く算出されても「関係がない」とは言えません。 - 異質性の混入
散布図上でデータが2つ以上のグループ(クラスター)に分かれている場合、全体での相関分析は意味をなさないことがあります。この場合、グループごとに層別して分析を行う必要があります。
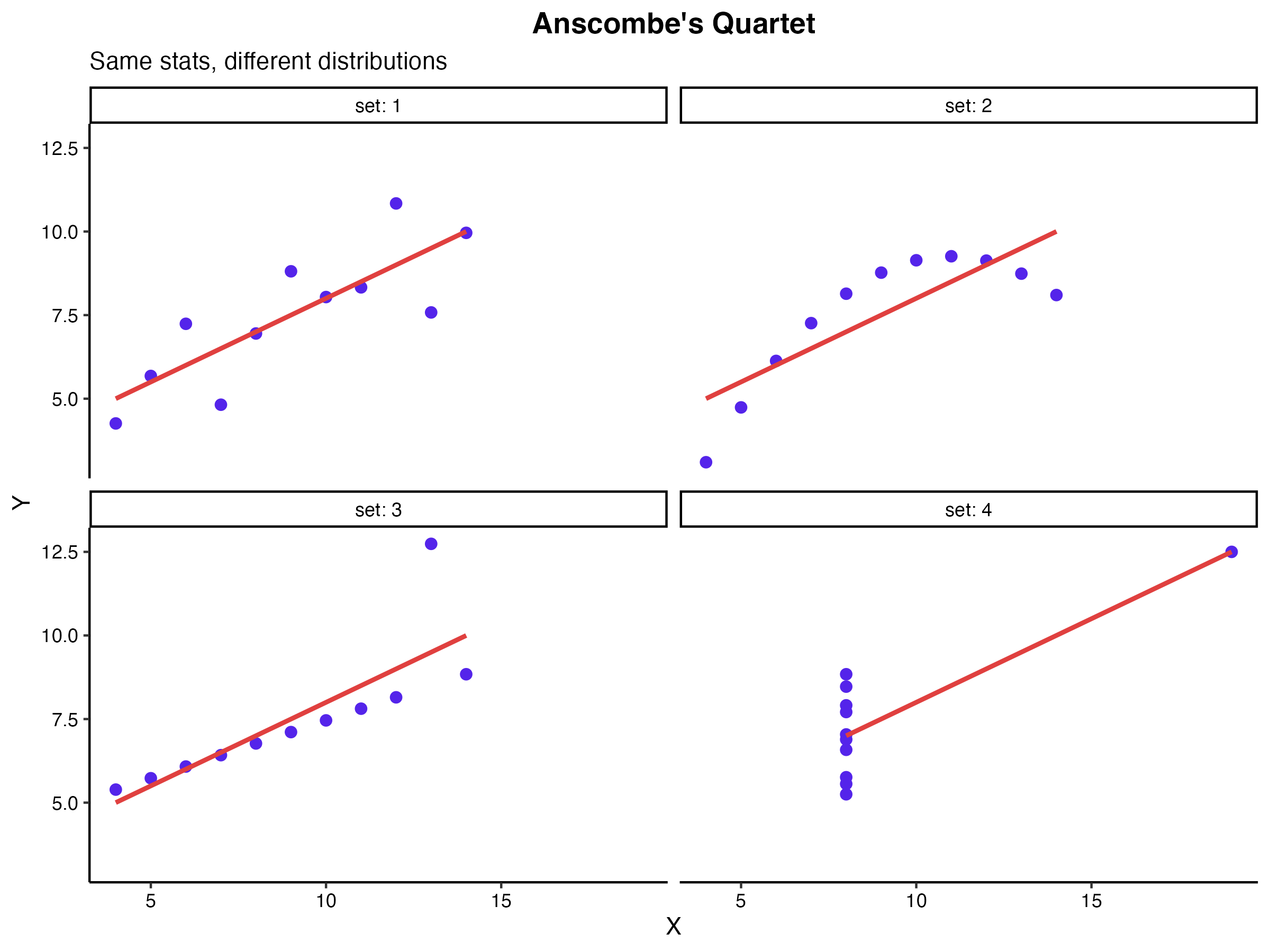
(図1. アンスコムの例(視覚化の重要性))
3. 統計的検定と信頼区間
算出された相関係数 $r$ が $0.5$ であったとしても、それだけで「中程度の相関がある」と断定することはできません。特にサンプルサイズ(データ数 $n$)が小さい場合、全く無関係な変数同士であっても偶然に高い相関が現れることがあるためです。
無相関の検定
「母集団における相関係数 $\rho$ は $0$ である」という帰無仮説 $H_0: \rho = 0$ を設定し、検定統計量 $t$ を用いて検定を行います。$n-2$ の自由度を持つ $t$ 分布に従う検定統計量は以下の通りです。
$$
t = \frac{r\sqrt{n-2}}{\sqrt{1-r^2}}
$$
得られた $p$ 値が有意水準(一般に $0.05$)を下回る場合、統計的に有意な相関があると判断します。しかし、サンプルサイズが極めて大きい場合、実務的に意味のない微小な相関(例:$r = 0.01$)であっても $p < 0.05$ となり有意と判定される「サンプルサイズの罠」に注意が必要です。
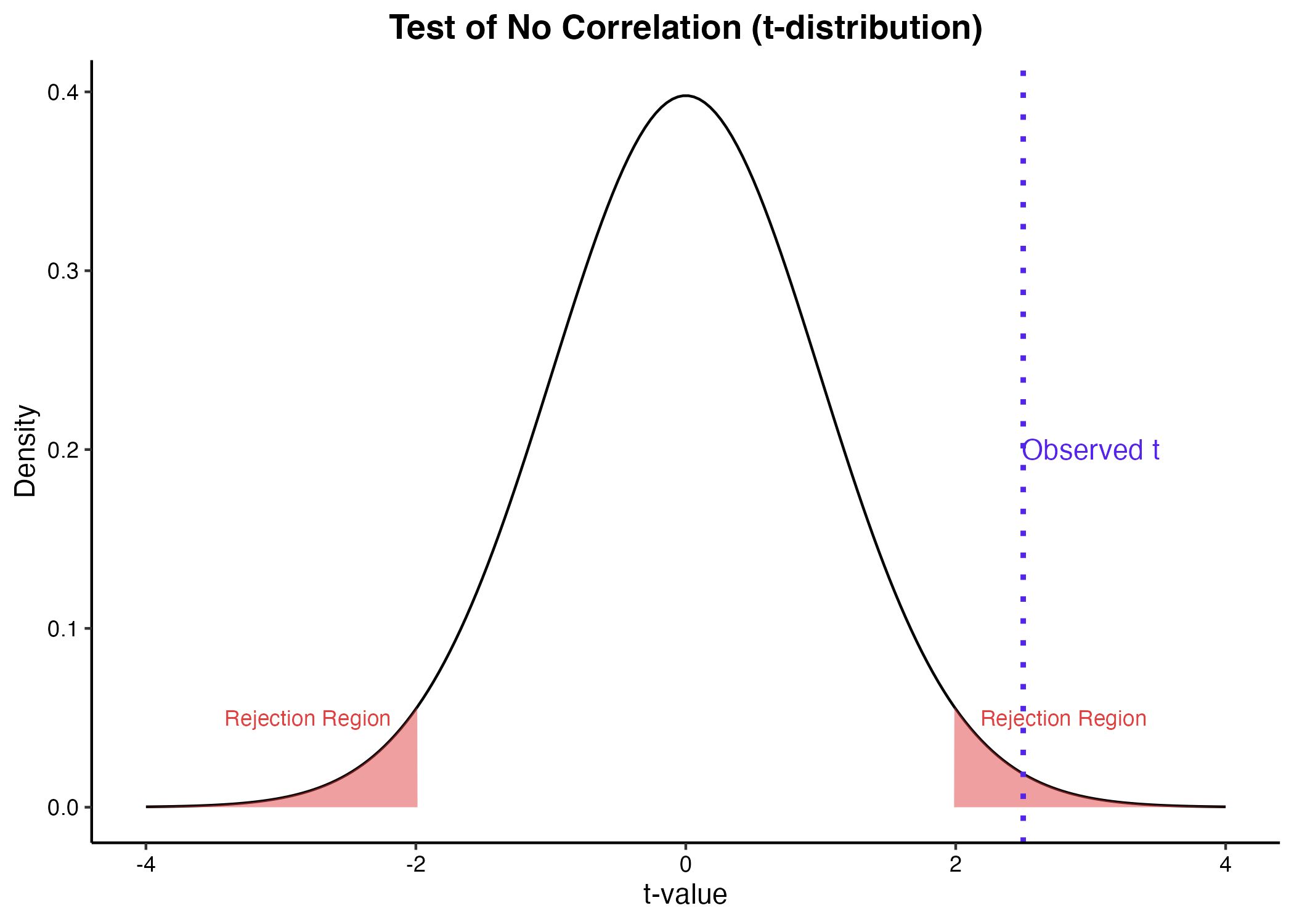
(図2. 無相関の検定におけるt分布と棄却域)
信頼区間の算出
点推定値としての $r$ だけでなく、母相関係数が存在する範囲を示す「信頼区間」を算出することで、推定の不確実性を評価します。相関係数の分布は非対称であるため、フィッシャーの $z$ 変換を用いて正規分布に近似させ、区間推定を行うのが一般的です。
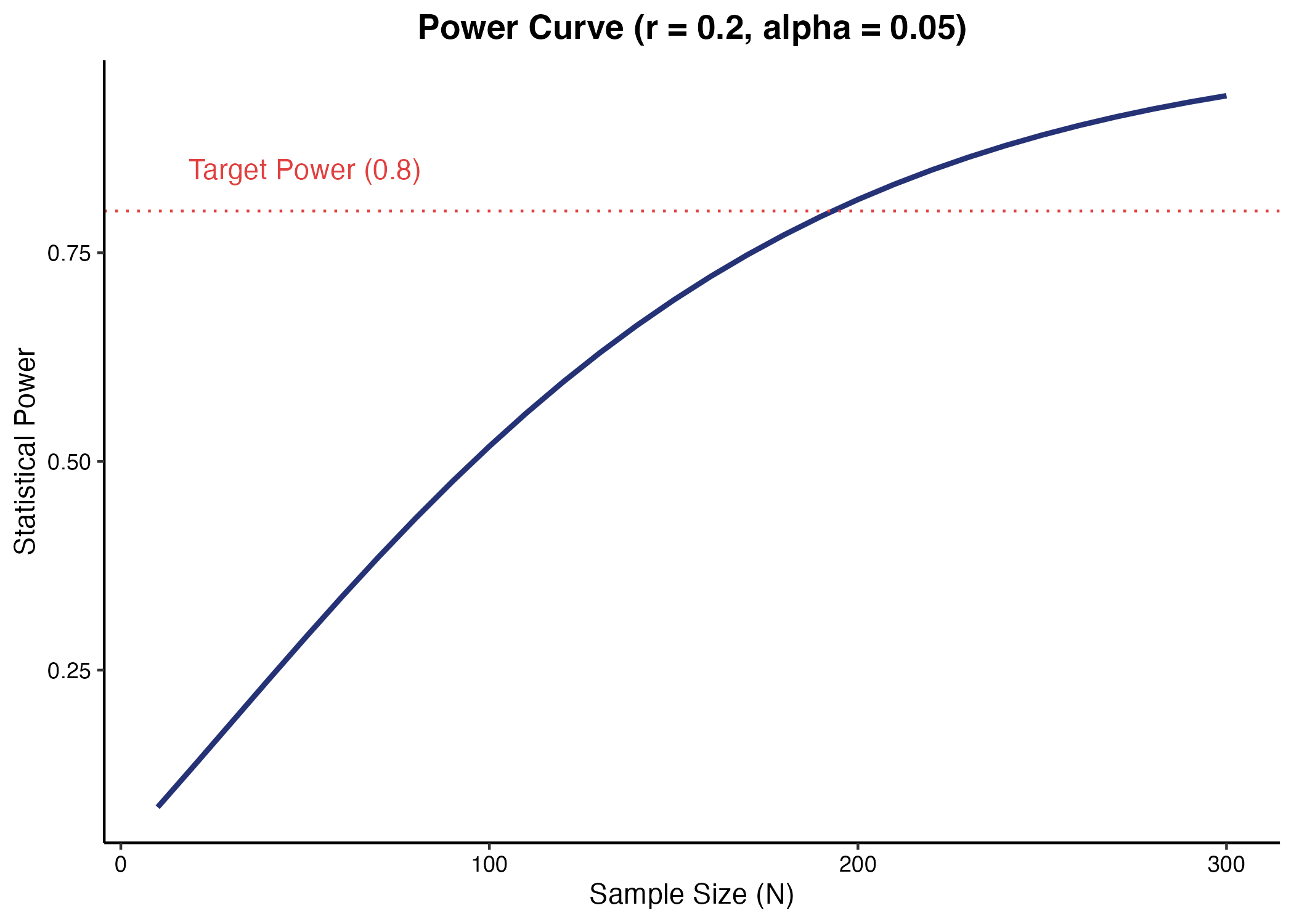
(図3. 検定力曲線(サンプルサイズと検出力))
4. 事後検証:疑似相関と因果の探索
統計的に有意な相関が確認された後、最後に実施すべきが「論理的・ドメイン的検証」です。数値上の相関が、真の実務的な関係性を示しているかを確認します。
- 時間的先行性の確認
原因とされる変数が結果よりも先に発生しているか、時系列データを用いて確認します。 - 偏相関分析による交絡の統制
第3の変数 $Z$ が関与している疑いがある場合、$Z$ の影響を除去した偏相関係数を算出し、疑似相関を排除します。
5. 【実務事例】製造現場におけるプロセス最適化フロー
相関分析の正しい手順がどのように品質改善に寄与するか、信頼性工学の視点から具体的な事例を紹介します。
背景
ある精密機器メーカーでは、最終製品の「動作精度」にばらつきが生じていました。設計チームは、部品の「加工時の切削速度」が精度に影響しているという仮説を立て、過去の製造ログ 1,000 件を抽出して分析を開始しました。
分析と問題点
初期の分析で、切削速度と精度の相関係数を算出したところ、$r = 0.25$ となり、関連性は低いと判断されかけました。しかし、正しい手順に従い散布図を作成したところ、特定の「材料ロット」ごとに相関の向きが異なることが判明しました。あるロットでは正の相関、別のロットでは負の相関を示しており、全体で集計したために相関が相殺(シンプソンのパラドックス)されていたのです。
解決策と手順の適用
1. 層別化: 材料ロットごとにデータを分割。
2. 再分析: 分割後の各グループで相関係数を再算出。結果、各グループ内では $r > 0.85$ という極めて強い相関が確認されました。
3. 有意性検定: 各グループで $p < 0.001$ を確認し、偶然ではないことを証明。
4. アクション: 材料の硬度(交絡変数)に合わせて切削速度を動的に変更する制御ルールを導入しました。これにより、動作精度のばらつきは 40% 低減されました。単なる一括計算に頼らず、視覚化と属性確認を重視した手順が、真の問題解決へと導いた事例です。
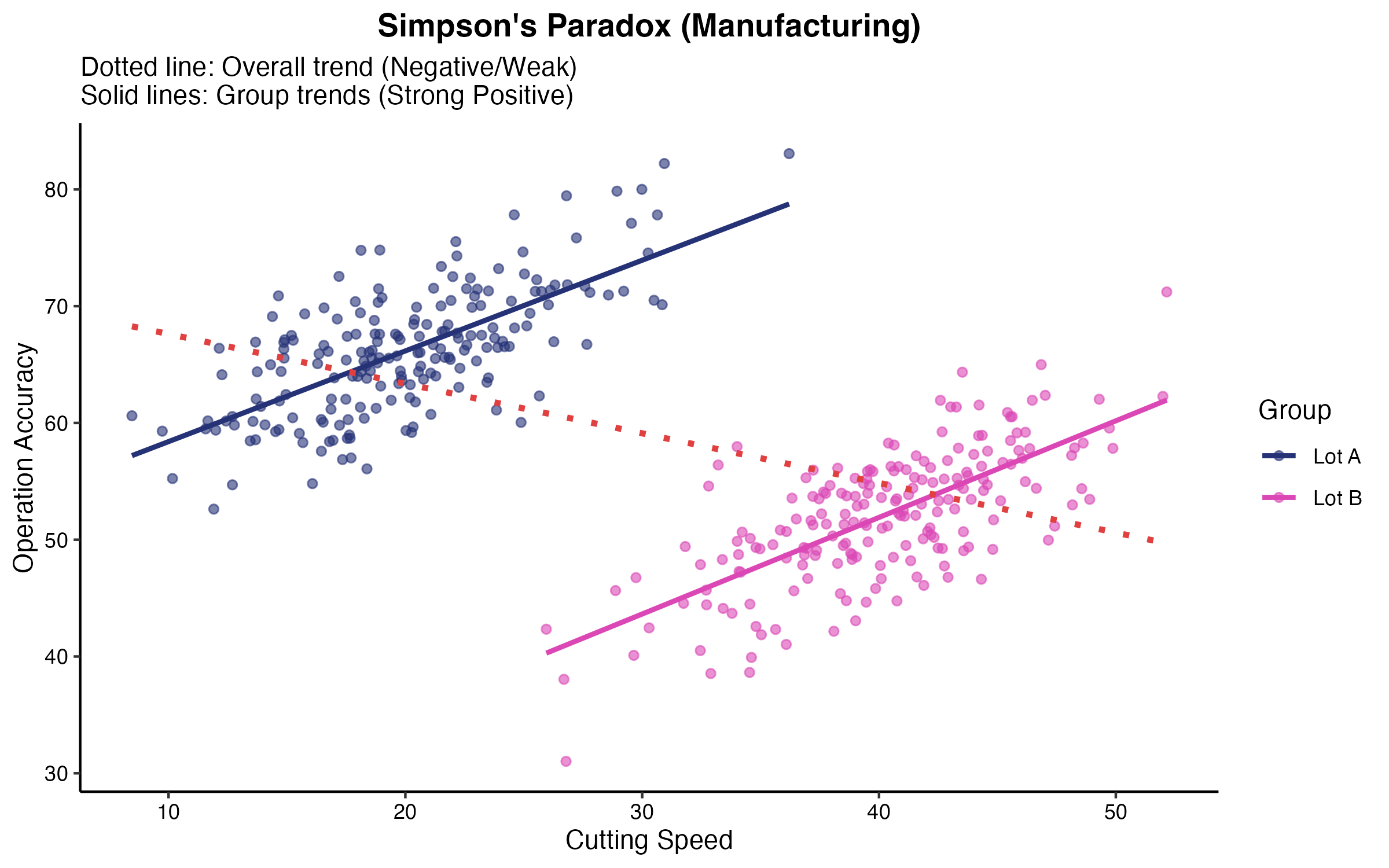
(図4. シンプソンのパラドックス(層別化の必要性))
まとめ
相関分析を正しく実行するためには、安易な計算に走るのではなく、データの性質(尺度・分布)の理解から始まり、散布図による視覚的検証、統計的検定による有意性の確認、そしてドメイン知識を用いた事後検証まで、一連のフローを厳密に踏むことが求められます。この構造化されたプロセスこそが、データに含まれるノイズや疑似相関を排し、真に価値のある知見を抽出するための唯一の道筋となります。

{kind=link}