
データ分析において、変数が2つの場合は単一の散布図や相関係数によってその関係性を評価することが可能です。しかし、現実のデータセットには数十から数千の変数が同時に存在することが一般的です。多変量データに対して、すべての変数ペア間の関係性を網羅的かつ系統的に把握するための数学的・構造的なアプローチが「相関行列(Correlation Matrix)」の導入です。
相関行列は、複数の変数間の相関係数を行列形式で一覧化したものであり、探索的データ分析(EDA)における全体像の把握だけでなく、主成分分析(PCA)や因子分析、重回帰分析における多重共線性の診断など、多変量解析の根幹をなす重要な概念です。本記事では、相関行列の数学的な定義とその固有の性質、視覚化の手法、および実務における具体的な応用事例について数理的背景を交えて詳解します。
相関行列の数学的定義
データセットに $p$ 個の連続型変数 $X_1, X_2, \dots, X_p$ が存在すると仮定します。任意の2つの変数 $X_i$ と $X_j$ の間のピアソンの積率相関係数を $r_{ij}$ としたとき、これらを $(i, j)$ 成分に配置した $p \times p$ の正方行列 $R$ が相関行列です。
$$
R = \begin{pmatrix}
r_{11} & r_{12} & \dots & r_{1p} \\
r_{21} & r_{22} & \dots & r_{2p} \\
\vdots & \vdots & \ddots & \vdots \\
r_{p1} & r_{p2} & \dots & r_{pp}
\end{pmatrix}
$$
この相関行列 $R$ は、各変数の分散と共分散をまとめた「分散共分散行列(Covariance Matrix)」から導出されます。変数間の共分散を $s_{ij}$、各変数の標準偏差を $s_i$ とすると、$r_{ij} = \frac{s_{ij}}{s_i s_j}$ と定義されます。したがって、分散共分散行列を $S$、各変数の標準偏差を対角成分に持つ対角行列を $D$ とすると、相関行列 $R$ は以下の行列表現で計算されます。
$$
R = D^{-1} S D^{-1}
$$
ここで、行列 $D$ は以下の通りです。
$$
D = \begin{pmatrix}
s_1 & 0 & \dots & 0 \\
0 & s_2 & \dots & 0 \\
\vdots & \vdots & \ddots & \vdots \\
0 & 0 & \dots & s_p
\end{pmatrix}
$$
この変換により、各変数の測定単位(スケール)の違いが標準化され、すべての要素が無次元の指標($-1 \leq r_{ij} \leq 1$)として扱えるようになります。
相関行列が持つ重要な数学的性質
相関行列 $R$ は、線形代数学的にいくつかの重要な性質を備えています。これらの性質を理解することは、後続の統計モデリングにおけるエラー(計算の非収束など)を未然に防ぐために不可欠です。
- 対称行列(Symmetric Matrix)
変数 $X_i$ と $X_j$ の相関と、変数 $X_j$ と $X_i$ の相関は定義上完全に一致します($r_{ij} = r_{ji}$)。したがって、相関行列は主対角線を軸として線対称となる対称行列($R = R^T$)です。 - 対角成分は常に1
ある変数とそれ自身の相関係数は常に最大値の1となります($r_{ii} = 1$)。そのため、相関行列の主対角成分(左上から右下への対角線)はすべて1で構成されます。 - 半正定値行列(Positive Semi-definite Matrix)
相関行列の固有値はすべて0以上となります。実データに基づく相関行列は原則として正定値(すべての固有値が正)ですが、変数間に完全な線形従属関係(一つの変数が他の変数の線形結合で完全に表現できる状態)が存在する場合、固有値の一部が0となり、行列式 $|R|$ が0になります。これはモデル構築において多重共線性(Multicollinearity)と呼ばれる致命的な問題の数学的兆候です。
分散共分散行列と相関行列の比較
多変量解析において、分散共分散行列と相関行列のどちらを基準に計算を進めるべきかは重要な選択となります。両者の特性を以下の表に整理します。
| 比較項目 | 分散共分散行列 ($S$) | 相関行列 ($R$) |
|---|---|---|
| 要素の値の範囲 | $-\infty$ から $\infty$(変数の単位に依存) | $-1$ から $1$(標準化され無次元) |
| 対角成分の意味 | 各変数の分散 ($s_i^2$) | 常に1(自身との相関) |
| 主な適用場面 | 変数の測定単位がすべて同一である場合、または元のスケールの分散を保持したい場合 | 変数の測定単位が異なる場合、または変数のスケールによる影響を排除したい場合 |
| 主成分分析(PCA)への影響 | 分散が大きい変数(桁数の大きい変数)の寄与が過大評価される | すべての変数が対等に扱われるため、単位の異なるデータ群の構造抽出に適している |
相関行列の視覚化手法
変数の数が5〜10個程度であれば、数値の行列を直接目で追うことも可能ですが、数十個の変数に膨れ上がると、数値の羅列から全体の構造を読み取ることは人間の認知能力を超えます。そこで、相関行列を視覚的に解釈するための「ヒートマップ(Heatmap)」や「コレログラム(Correlogram)」といった手法が標準的に用いられます。
ヒートマップでは、相関係数の数値の大きさを「色の濃淡」や「色相」に変換します。一般的に、強い正の相関($r$ が1に近い)を濃い赤や青、強い負の相関($r$ が-1に近い)をその補色、無相関($r$ が0に近い)を白などの無彩色で表現します。この視覚化により、以下の情報を一目で抽出することが可能になります。
- 強い相関を持つ変数群(クラスタ)の特定
特定の変数同士がブロック状に強い色を示している場合、それらの変数が背後で同じ潜在的な要因(因子)を共有していることを示唆します。 - 孤立した変数の発見
他のどの変数とも相関を持たない(色が薄い)変数は、独立した情報を持っているか、あるいは分析目的においてノイズとなっている可能性があります。
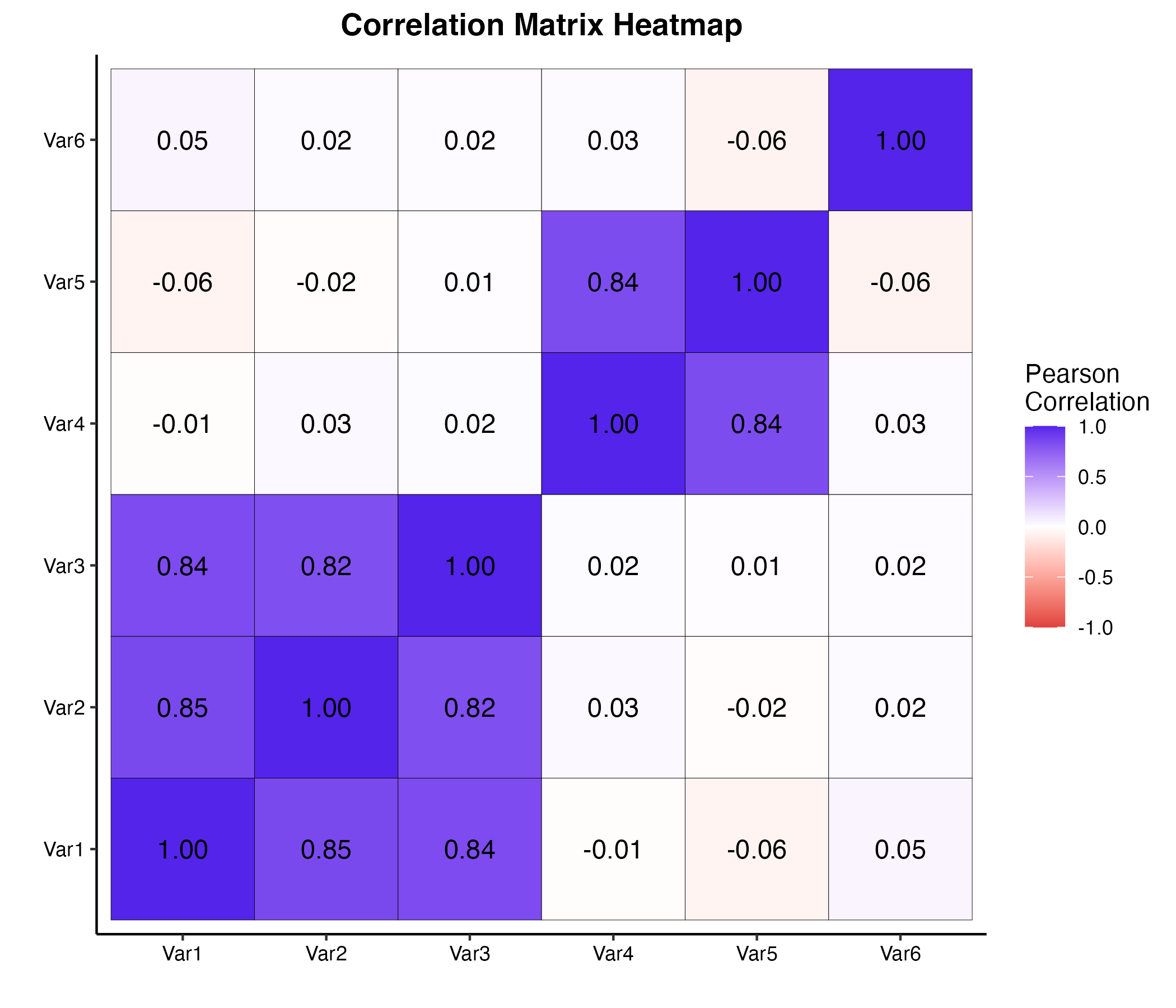
(図1. 相関行列のヒートマップ(クラスタと孤立変数の視覚化))
実務における相関行列の適用事例
相関行列の理論は、様々な産業分野においてデータ構造の把握とリスク管理の基盤として活用されています。具体的な実務事例を2つ紹介します。
金融工学におけるポートフォリオ・リスク管理
背景
ある資産運用会社において、投資家向けに複数の株式銘柄(50銘柄)を組み合わせたファンドを組成するプロジェクトが進行しています。目的は、市場全体の暴落時にもファンド全体の資産価値の目減りを最小限に抑える(リスクを分散する)ことです。
分析アプローチ
過去5年間の各銘柄の日次収益率(リターン)のデータから、$50 \times 50$ の相関行列を算出し、ヒートマップで視覚化しました。現代ポートフォリオ理論(Markowitzの平均・分散アプローチ)において、ファンド全体のリスク(分散)は、各銘柄単体のリスクだけでなく、銘柄間の「共分散(相関)」に大きく依存します。
解釈とアクション
相関行列を分析した結果、同一業種(例:半導体関連銘柄)のグループ内では相関係数が $r > 0.8$ と極めて高い連動性を示していることが確認されました。これは、業界特有のショックが発生した際、これらの銘柄が同時に下落することを意味します。一方で、エネルギー関連銘柄とヘルスケア関連銘柄の間には $r \approx -0.2$ という弱い負の相関が確認されました。運用チームは相関行列の数値を最適化アルゴリズムに入力し、正の相関が強すぎる銘柄群の構成比率を下げ、負の相関や無相関を示す異業種銘柄を適切に組み入れることで、期待収益を維持したままポートフォリオ全体のリスク(ボラティリティ)を数学的に最小化する構成比率を決定しました。
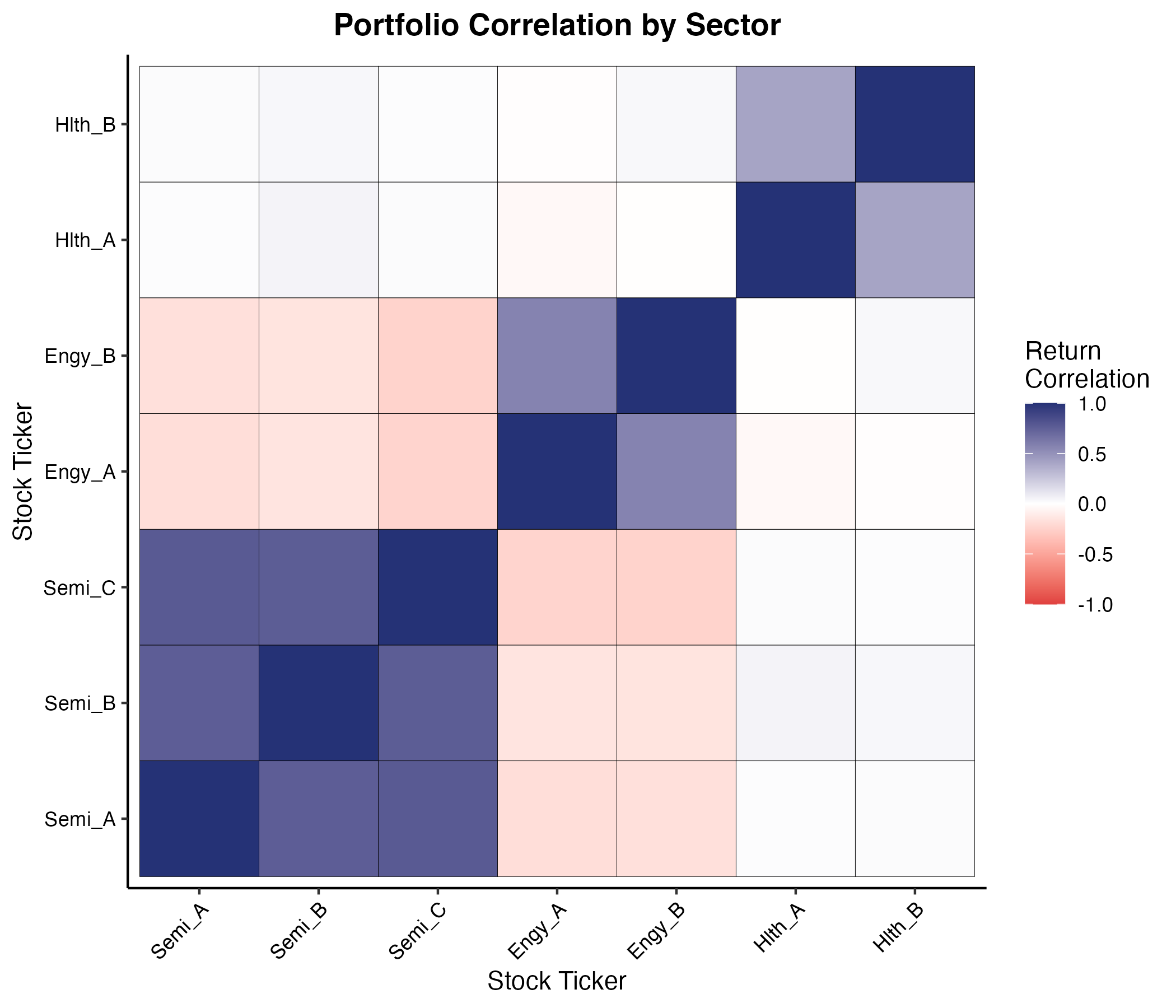
(図2. セクター別ポートフォリオの相関ヒートマップ)
製造業におけるセンサーデータの次元削減
背景
化学プラントの反応炉において、製品の品質異常を検知するために、炉内の様々な箇所に計100個の温度・圧力センサーが設置されています。データ分析チームは、これらのセンサーデータを用いて品質予測モデル(機械学習モデル)を構築しようとしていますが、計算コストの増大と過学習(オーバーフィッティング)が懸念されていました。
分析アプローチ
100個のセンサーデータから $100 \times 100$ の相関行列を算出し、行列内の要素を確認しました。その結果、物理的に近接して設置されている複数の温度センサー群において、相関係数が $r > 0.98$ とほぼ完全な正の相関関係にあることが判明しました。
解釈とアクション
相関係数が1に近い変数群をすべて予測モデルに投入すると、多重共線性によってモデルのパラメータ推定が不安定になり、予測精度が逆に悪化する危険性があります。また、同じ情報を持つデータを重複して保持することはリソースの浪費です。チームは相関行列の情報を基に、相関が $0.95$ を超えるセンサー群については代表となる1つのセンサーのデータのみを残し、他を特徴量から除外する処理(特徴量選択)を行いました。これにより、モデルの安定性が担保されるとともに、監視すべきセンサー数が削減され、プラントの保守運用コストの最適化にも寄与しました。

(図3. 極めて強い相関を持つセンサーデータの散布図)
の基本")
{kind=link}