
これまでの項では、主に2つの連続変数を対象としたピアソンの積率相関係数や、順位データを扱うスピアマンの順位相関係数について解説しました。しかし、実際のデータ分析において、性別(男性/女性)、試験の合否(合格/不合格)、製品の不良(良品/不良品)など、2つの値しか持たない「二値変数(ダミー変数)」と連続変数の関係性、あるいは二値変数同士の関係性を評価する場面が多々存在します。
本項では、一方が連続変数で他方が二値変数の場合に用いられる「点双列相関係数(Point-Biserial Correlation Coefficient)」と、両方が二値変数の場合に用いられる「ファイ係数(Phi Coefficient, $\phi$)」の理論的背景と、それぞれの実務における適用事例について解説します。これらは全く新しい指標ではなく、実はピアソンの積率相関係数を特定のデータ条件に適用し、数式を簡略化した数学的同値表現です。
点双列相関係数の数理的背景
点双列相関係数 $r_{pb}$ は、連続変数 $X$ と、0または1の値をとる二値変数 $Y$ の間の相関を測定します。二値変数 $Y$ が1であるグループと0であるグループの2つにデータを分割し、それぞれのグループにおける連続変数の平均値の差を評価する指標として機能します。
二値変数をそのまま0と1の数値として扱い、ピアソンの積率相関係数の公式に代入して整理すると、以下の計算式が導出されます。
$$
r_{pb} = \frac{\bar{X}_1 – \bar{X}_0}{S_X} \sqrt{\frac{n_1 n_0}{n^2}}
$$
- $\bar{X}_1, \bar{X}_0$ は、それぞれ $Y=1$ および $Y=0$ のグループにおける連続変数 $X$ の標本平均。
- $S_X$ は、連続変数 $X$ 全体の標本標準偏差。
- $n_1, n_0$ は、それぞれのグループのサンプルサイズ(観測数)。
- $n$ は、全体のサンプルサイズ($n = n_1 + n_0$)。
この式から明らかなように、点双列相関係数は「2群の平均値の差($\bar{X}_1 – \bar{X}_0$)」に比例します。つまり、2群間で連続変数の分布が大きく離れているほど、相関が強い(1または-1に近づく)と解釈されます。視覚的には、二値変数をX軸、連続変数をY軸とした「箱ひげ図(Boxplot)」を作成し、2つの箱の高さ(中央値や四分位範囲)のズレを確認することで関係性を直感的に把握できます。
なお、点双列相関係数は、2群の平均値の差を検定する「スチューデントのt検定(Student’s t-test)」と密接な関係にあり、算出された $r_{pb}$ の二乗(決定係数)は、t検定における効果量(Effect Size)と数学的に一致します。
ファイ係数($\phi$係数)の数理的背景
ファイ係数 $\phi$ は、2つの変数がともに二値変数(カテゴリカルデータ)である場合の相関関係を測定します。アンケートにおける「はい/いいえ」の回答同士の関連性や、特定の属性と購買の有無などの関係を定量化する際に用いられます。
2つの二値変数をクロス集計し、以下のような $2 \times 2$ の分割表(Contingency Table)を作成します。
| 変数Y = 1 | 変数Y = 0 | 合計 | |
|---|---|---|---|
| 変数X = 1 | $a$ | $b$ | $a + b$ |
| 変数X = 0 | $c$ | $d$ | $c + d$ |
| 合計 | $a + c$ | $b + d$ | $n = a + b + c + d$ |
各セル内の頻度($a, b, c, d$)を用いて、ファイ係数は以下のように定義されます。
$$
\phi = \frac{ad – bc}{\sqrt{(a+b)(c+d)(a+c)(b+d)}}
$$
この計算式も、2つの二値変数をそれぞれ0と1の数値ベクトルと見なしてピアソンの積率相関係数を計算した結果と完全に一致します。ファイ係数は $-1 \leq \phi \leq 1$ の範囲をとり、対角成分($a$ と $d$)の度数が相対的に大きいほど正の相関が強く、非対角成分($b$ と $c$)の度数が大きいほど負の相関が強くなります。データ全体の偏りや割合の分布を視覚的に捉えるためには、面積で度数を表現する「モザイクプロット(Mosaic Plot)」の活用が有効です。
また、ファイ係数は独立性の検定に用いられるピアソンのカイ二乗統計量 $\chi^2$ とも数理的なつながりがあり、$\phi = \sqrt{\chi^2 / n}$ の関係が成立します。
実務事例の解説
理論的な指標が実際のビジネスや研究領域においてどのように解釈され、意思決定に活用されているかを解説します。
製造業における品質管理(点双列相関係数の適用)
ある精密機器メーカーの組み立てラインにおいて、完成品の機能テスト結果(合格=1、不合格=0という二値変数)と、はんだ付け工程におけるヒーターの設定温度(連続変数)の関係性を評価する課題が発生しました。
点双列相関係数を算出したところ、$r_{pb} = -0.65$ という強い負の相関が確認されました。これは「ヒーターの設定温度が高いほど、テスト結果が不合格(0)になる傾向が強い」ことを示しています。品質管理部門はこの結果と箱ひげ図による分布のズレを根拠とし、ヒーター温度の上限に新たな閾値を設定するプロセス改善を実行し、歩留まりの改善に寄与しました。
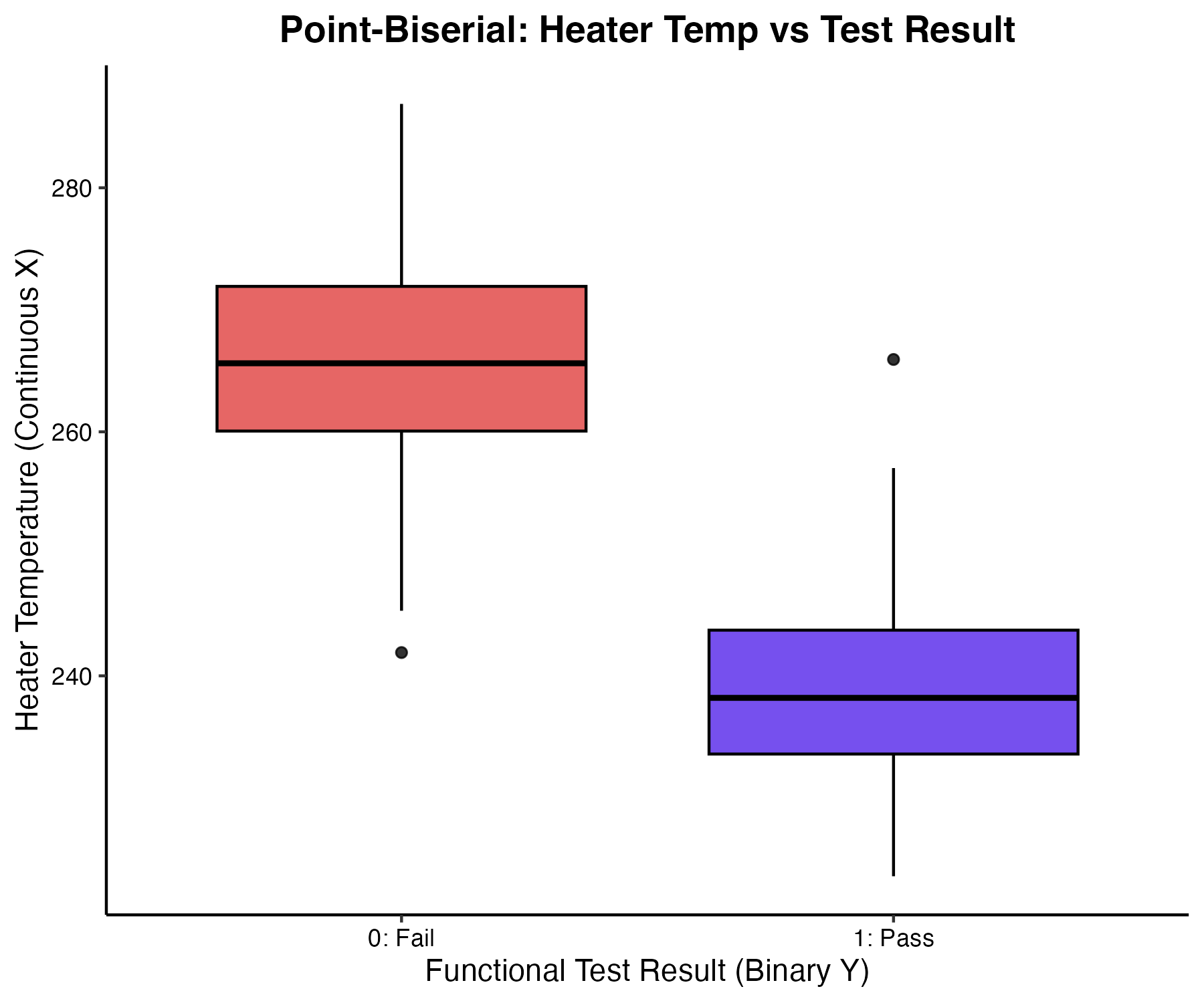
(図1. ヒーター設定温度とテスト結果の関係(箱ひげ図))
臨床試験・マーケティングのA/Bテスト(ファイ係数の適用)
Webサービスのマーケティング部門において、新規ユーザー向けのオンボーディング画面のデザインを2パターン用意し、どちらが有料プランへの移行(コンバージョン)に寄与するかをA/Bテストで検証しました。
「画面デザイン(パターンA=1、パターンB=0)」と「有料プラン移行(移行した=1、移行しなかった=0)」の2つの二値変数から $2 \times 2$ のクロス集計表を作成し、ファイ係数を算出しました。結果として $\phi = 0.12$ となり、正の相関(パターンAの方が移行しやすい傾向)は見られたものの、その強さは極めて微弱であることが定量的に示されました。これにより、デザイン変更によるビジネスインパクトは限定的であると判断され、開発リソースを別の機能改善施策へ再配分する経営判断が下されました。

(図2. 画面デザイン別の有料プラン移行率(100%積み上げ棒グラフ))
二値データが関わる変数の相関関係を評価する際、変数の尺度(連続か二値か)に応じて適切な指標(点双列相関係数、ファイ係数)を選択し、それぞれに対応するグラフ(箱ひげ図、モザイクプロット)と併用することで、データ生成のメカニズムをより正確に把握することが可能になります。

{kind=link}