
これまでの項では、連続変数や順序変数を対象とした相関係数について解説しました。しかし、実際のデータセットには「顧客の居住地域」「商品のカテゴリー」「製造ラインの識別番号」といった、数値的な大小関係を持たない名義尺度のデータ(カテゴリデータ)が頻繁に出現します。このような名義尺度同士の関連性の強さを定量化する代表的な指標が、クラメールの連関係数(Cramér’s V)です。
ピアソンの積率相関係数などが直線的な関係性を評価するのに対し、クラメールの連関係数は2つのカテゴリ変数が独立である(全く関連がない)状態からどの程度逸脱しているかを測定します。本項では、その数理的基盤であるカイ二乗統計量からの導出と、実務における解釈方法について詳述します。
カテゴリデータにおける独立性とカイ二乗統計量
2つの名義尺度間の関連性を評価する出発点は、クロス集計表(分割表)の作成です。行に変数 $X$(カテゴリ数 $r$)、列に変数 $Y$(カテゴリ数 $c$)を配置した $r \times c$ の分割表を想定します。
各セルにおける実際の観測度数を $O_{ij}$ とし、2つの変数が完全に独立であると仮定した場合に期待される度数(期待度数)を $E_{ij}$ とします。期待度数 $E_{ij}$ は、行の周辺度数 $R_i$ と列の周辺度数 $C_j$、および全体サンプルサイズ $n$ を用いて、$E_{ij} = (R_i \times C_j) / n$ として計算されます。
観測度数と期待度数の乖離の大きさを表す指標が、ピアソンのカイ二乗統計量 $\chi^2$ です。以下の式で定義されます。
$$
\chi^2 = \sum_{i=1}^{r} \sum_{j=1}^{c} \frac{(O_{ij} – E_{ij})^2}{E_{ij}}
$$
この $\chi^2$ 値が大きいほど、2つの変数が独立であるという仮定からデータが遠く離れている(すなわち、何らかの関連性がある)ことを意味します。しかし、$\chi^2$ 値自体はサンプルサイズ $n$ や分割表のサイズ(カテゴリ数)に依存して上限なく増大するため、異なるデータセット間で関連性の強さを直接比較する指標としては不適切です。
クラメールの連関係数の定義と性質
$\chi^2$ 統計量の持つサンプルサイズと分割表サイズへの依存性を補正し、$0$ から $1$ の範囲に標準化した指標がクラメールの連関係数 $V$ です。以下の式で算出されます。
$$
V = \sqrt{\frac{\chi^2}{n \cdot \min(r-1, c-1)}}
$$
ここで、$\min(r-1, c-1)$ は、行数 $r$ から1を引いた値と、列数 $c$ から1を引いた値のうち、小さい方を指します。この式の分母は、与えられたサンプルサイズ $n$ と分割表の次元において $\chi^2$ がとり得る理論上の最大値に相当します。したがって、$V$ は常に $0 \le V \le 1$ の範囲に収まります。
- $V = 0$ は、2つの変数が完全に独立であり、一切の関連性がないことを示します(観測度数と期待度数が完全に一致)。
- $V = 1$ は、一方の変数のカテゴリが定まれば、もう一方の変数のカテゴリが完全に決定される(完全な連関がある)ことを示します。
分割表の構造やカテゴリ間の関連性を視覚的に把握する手法として、モザイクプロットや100%積み上げ棒グラフが用いられます。モザイクプロットでは、各矩形の面積が該当するセルの観測度数に比例し、幅と高さの比率から独立性からの逸脱(連関の存在)を直感的に読み取ることができます。
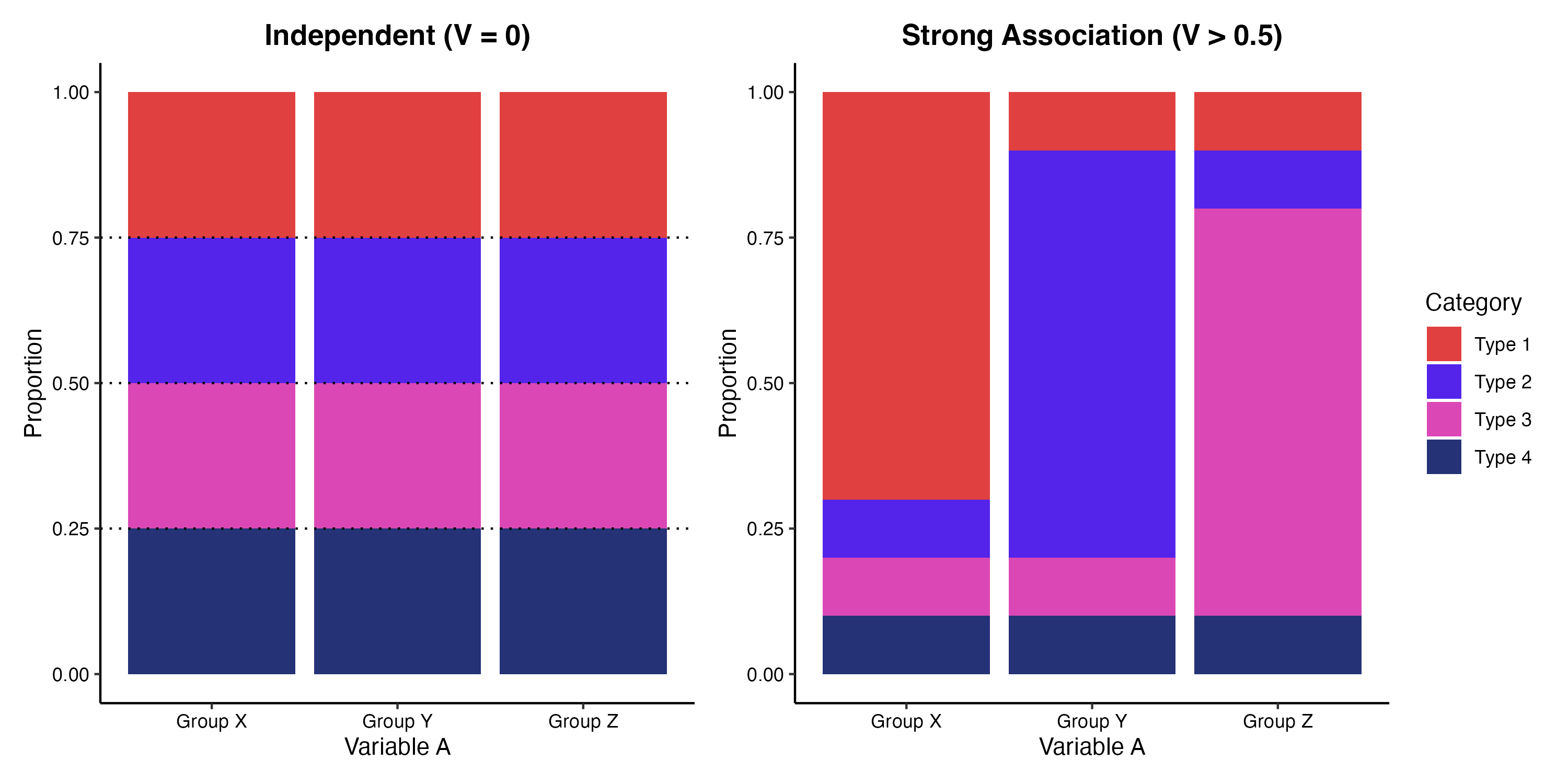
(図1. 独立と連関の概念図(100%積み上げ棒グラフ))
クラメールの連関係数の評価基準と注意点
ピアソンの相関係数($r > 0.7$ で強い相関など)とは異なり、クラメールの連関係数に対する一律の評価基準を設定することは推奨されません。自由度(分割表のサイズ)によって、$V$ の値が持つ実質的な意味合いが変化するためです。自由度が大きい(カテゴリ数が多い)場合、比較的小さな $V$ の値であっても、実務上は有意かつ強い関連性を示しているケースが存在します。
また、クラメールの連関係数は「関連性の強さ」を示す無方向の指標であり、正の相関・負の相関といった「方向性」の概念を持たない点に留意する必要があります。係数が高い場合、具体的にどのカテゴリの組み合わせがその連関に寄与しているか(残差分析など)をクロス集計表に戻って確認するプロセスが不可欠です。
実務事例1 小売業における顧客獲得チャネルと購買カテゴリの関連性
背景
ある総合オンラインショップにおいて、顧客が最初にサイトを訪問した際の「流入チャネル(自然検索、SNS広告、アフィリエイト、メールマガジン)」と、初回に購入した「商品のカテゴリ(家電、日用品、衣料品、食品)」の間に関連性があるかを評価する課題が生じました。
分析アプローチ
過去1年間の新規顧客10,000名分のデータを抽出し、$4 \times 4$ のクロス集計表を作成しました。カイ二乗検定によって統計的な有意性を確認した上で、関連性の強さを測るためにクラメールの連関係数を算出したところ、$V = 0.42$ と評価されました。
解釈とアクション
自由度3($\min(4-1, 4-1)$)において $V = 0.42$ という値は、実質的かつ明確な連関が存在することを示しています。モザイクプロットを用いて内訳を詳細に確認した結果、「SNS広告」から流入した顧客は「衣料品」を、「自然検索」から流入した顧客は「家電」を初回購入する割合が、独立の仮定(全体の平均的割合)から大きく上回っていることが判明しました。この結果に基づき、各流入チャネルのランディングページに表示する推奨商品のロジックを最適化し、初回購入のコンバージョン率を改善しました。
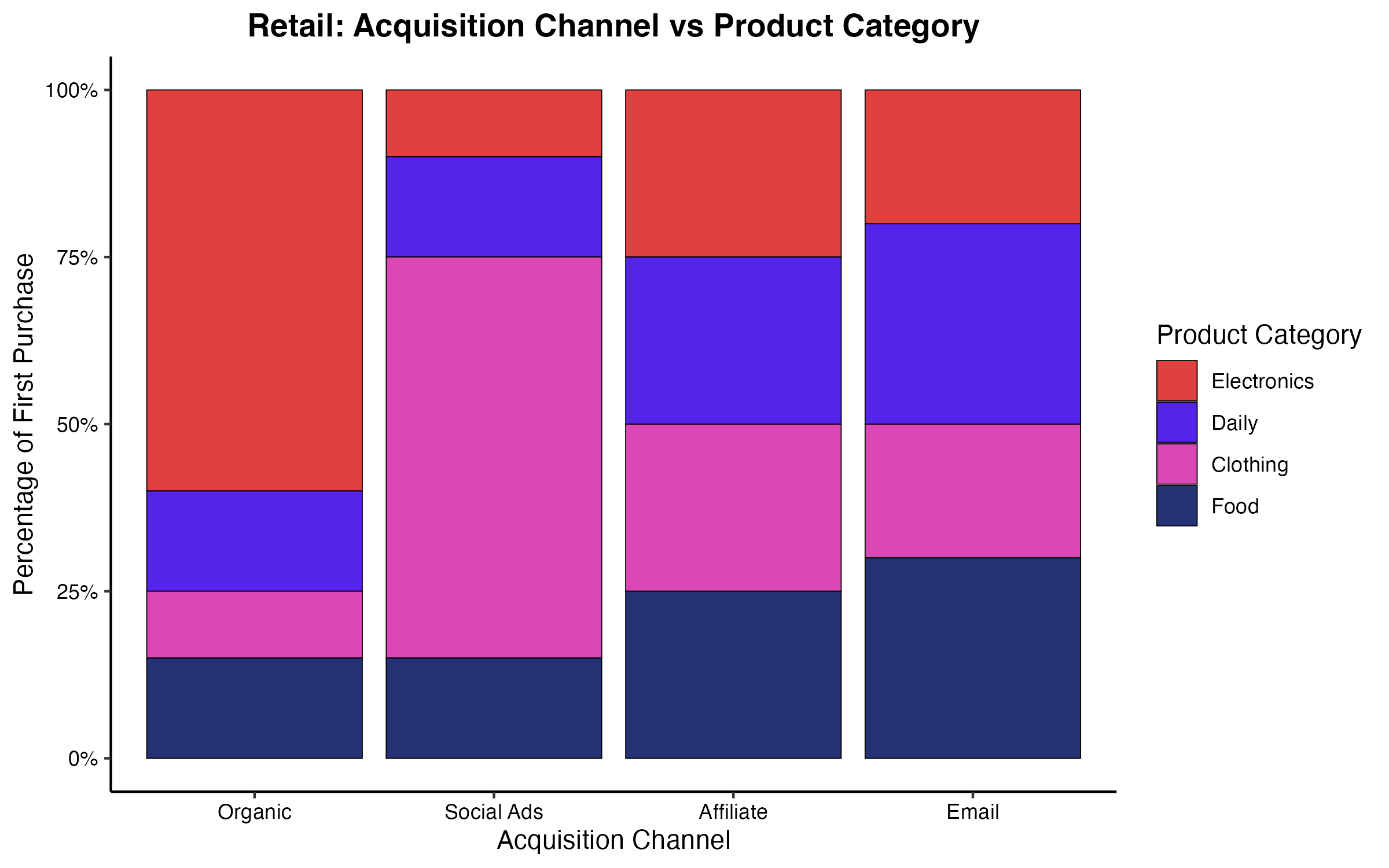
(図2. 流入チャネル別の初回購入カテゴリ割合)
実務事例2 製造業における生産ラインと不良品要因の関連性
背景
電子部品の製造工場において、最終検査工程で弾かれた不良品のデータ分析が行われました。分析の目的は、3つの「生産ライン(Aライン、Bライン、Cライン)」と、発生した「不良の要因(寸法エラー、表面キズ、接点不良、その他)」に関連性があるかを特定することです。
分析アプローチ
直近1ヶ月間で発生した不良品800個のデータを用い、$3 \times 4$ のクロス集計表からクラメールの連関係数を計算しました。算出された値は $V = 0.55$ でした。
解釈とアクション
この値は、生産ラインの違いによって発生しやすい不良要因の傾向が明確に異なることを意味しています。観測度数と期待度数の差(標準化残差)を検証すると、Bラインでは「表面キズ」が特異的に多く、Cラインでは「接点不良」が集中していることが分かりました。この定量的根拠をもとに、Bラインの搬送ベルトの摩擦点検と、Cラインのハンダ付け工程の温度設定見直しという、各ラインに特化した原因究明と設備調整が迅速に実施されました。
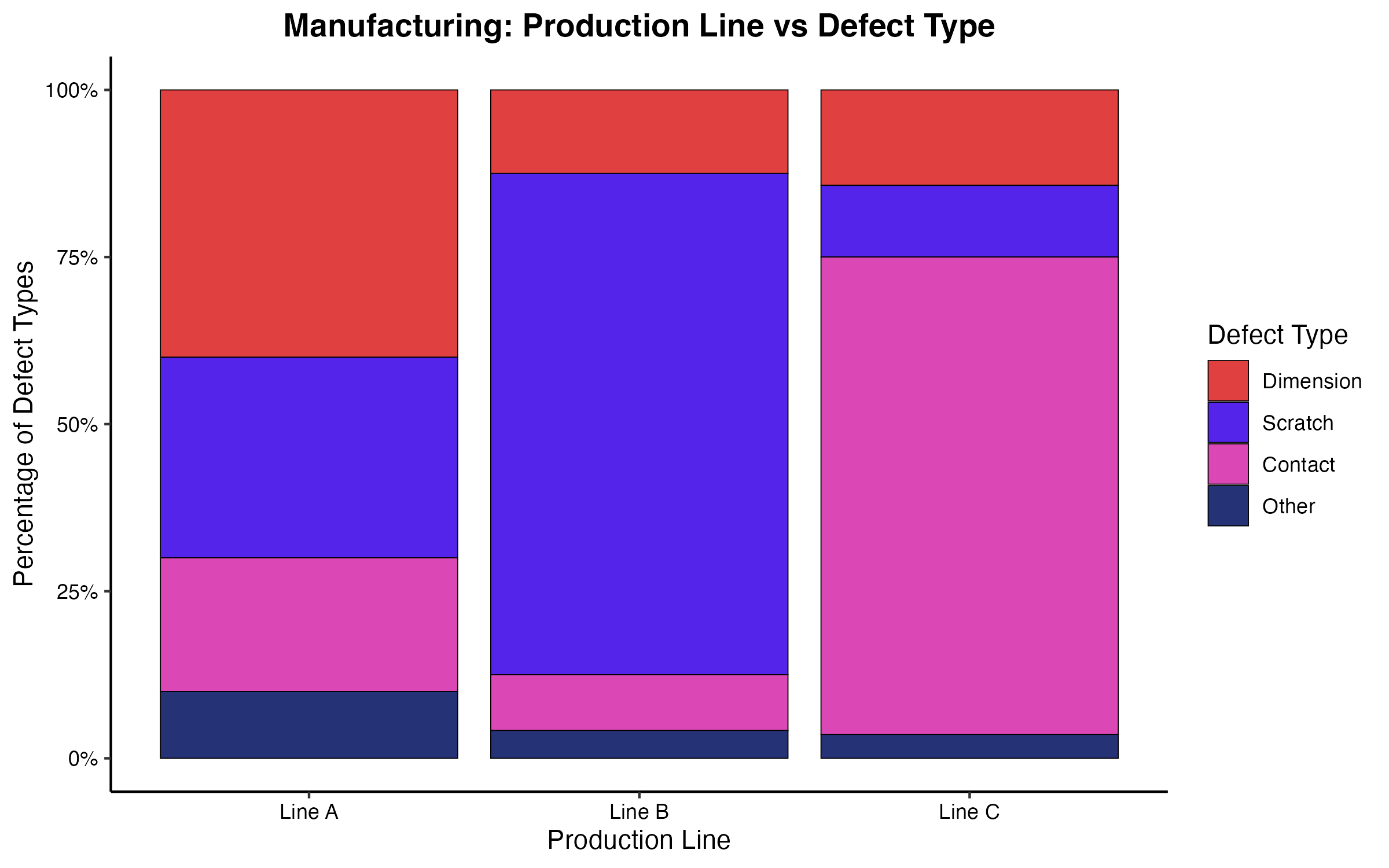
(図3. 生産ライン別の不良要因発生割合)

{kind=link}